微軟Azure AI新增Phi、Jais等,40種新大模型
原文來源:AIGC開放社區
 圖片來源:由無界 AI生成
圖片來源:由無界 AI生成
微軟在官方宣佈在Azure AI雲開發平臺中,新增了Falcon、Phi、Jais、Code Llama、CLIP、Whisper V3、Stable Diffusion等40個新模型,涵蓋文本、圖像、代碼、語音等內容生成。
開發人員只需要通過API或SDK就能快速將模型集成在應用程式中,同時支持數據微調、指令優化等量身定製功能。
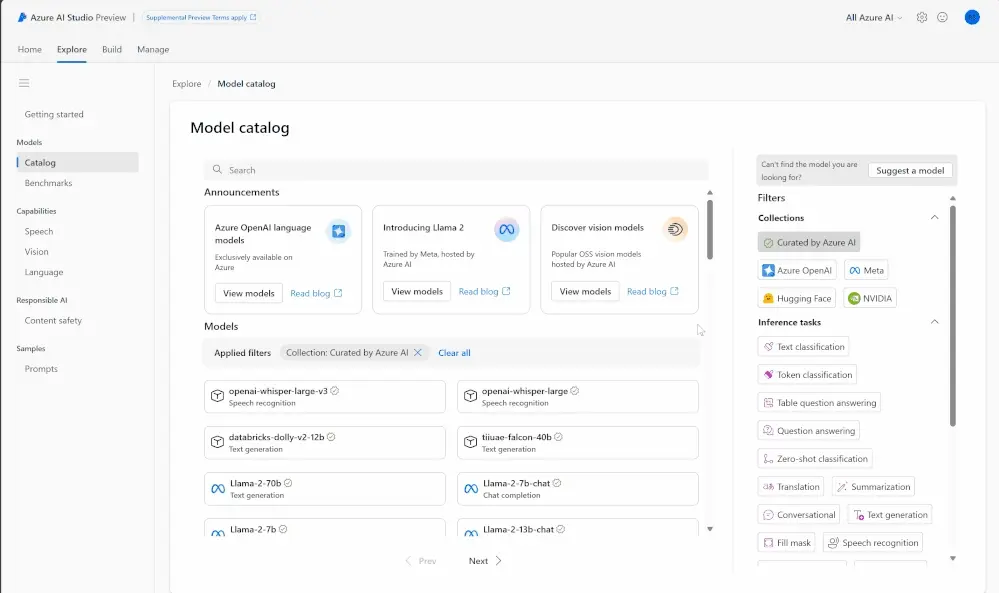
此外,開發人員可通過關鍵字搜索,在Azure AI的“模型超市”中迅速找到適合自己的產品,例如,輸入“代碼”兩字,就能顯示相應的模型。
體驗位址:
 以下是部分知名新增模型的簡單介紹
以下是部分知名新增模型的簡單介紹
耳語 V3
Whisper V3是OpenAI最新開發的語音模型,使用了100 萬小時弱標記音訊和400萬小時的偽標記音訊的多語言數據進行了訓練,同時接受了語音辨識和語音翻譯方面的訓練。 支援語音翻譯、轉錄等功能。
穩定擴散
Stable Diffusion是由Stability AI開發的文本生成圖像擴散模型,可生成素描、油畫、卡通、3D等多種類型圖片,也是目前最強開源擴散模型之一。
微軟Azure AI將提供Stable-Diffusion-V1-4、Stable-Diffusion-2-1 、Stable-Diffusion-V1-5 、Stable-Diffusion-Inpainting 、Stable-Diffusion-2-Inpainting五種不同版本模型。
Phi
Phi-1-5有 13億參數Transformer架構的模型。 使用了與 Phi-1 相同的數據進行了訓練,並增加了一個新的數據源,該數據源由各種NLP合成文本組成。
在評估測試常識、語言理解和邏輯推理的基準時, Phi-1.5 成為參數少於 100 億的模型中,成為最出色的模型之一。 該模型可以寫詩,起草電子郵件,創作故事,總結文本,編寫 Python 代碼等。
Phi-2有27億參數,與 Phi-1-5 相比,其推理能力和安全措施有了顯著提高,但與業內其他Transformer 架構模型相比參數較小,但性能依然強悍。
獵鷹
Falcon(獵鷹)模型是由阿聯酋阿布達比研究室出品的大語言模型,使用了1萬億訓練數據集,支援文本生成、內容總結等功能,支援Falcon-40b、Falcon-40b-Instruct 、Falcon-7b-Instruct和Falcon-7b四種模型。
SAM
SAM(Segment Anything Model)是由Meta開發的圖像分割模型,可根據提示快速分割圖像。 SAM在1100萬張圖像和11億掩模的數據集上進行了訓練。
SAM支援0樣本訓練支援新的圖像分割任務,目前有Facebook-Sam-Vit-Large 、Facebook-Sam-Vit-Huge 、Facebook-Sam-Vit-Base 三種模型。
剪輯
CLIP是由OpenAI開發的多模態AI模型,在大量的圖像和文本對上進行訓練,能夠理解圖像內容並將其與自然語言描述相關聯。 CLIP通過對圖像和文字進行共同的表示學習,極大地提升了計算機視覺的各種任務,包括分類、物件檢測、圖像字幕和更多。
目前有OpenAI-CLIP-Image-Text-Embeddings-ViT-Base-Patch32、OpenAI-CLIP-ViT-Base-Patch32和OpenAI-CLIP-ViT-Large-Patch14三個版本。
代碼駱駝
Code Llama是Meta開發的專注開發領域的模型,通過文本就能生成、審核、改寫代碼,擁有CodeLlama-34b-Python 、CodeLlama-13b-Instruct等8個版本,是目前最強開原始程式碼模型之一。