Source originale : Conseil quotidien de l’innovation scientifique et technologique
 Source de l’image : générée par Unbounded AI
Source de l’image : générée par Unbounded AI
Le 25, heure locale, OpenAI a annoncé que ChatGPT avait reçu une mise à jour majeure : ce chatbot peut désormais « voir, parler et écouter » - en d’autres termes, ChatGPT a ajouté des fonctions de voix et d’image. Au cours des deux prochaines semaines, les utilisateurs Plus et les utilisateurs professionnels pourront découvrir les nouvelles fonctionnalités, et d’autres groupes d’utilisateurs tels que les développeurs devraient en faire l’expérience dans un avenir proche.
Parmi eux, la capacité de compréhension d’images de ChatGPT a attiré le plus l’attention du monde extérieur. Selon les rapports, les utilisateurs peuvent afficher une ou plusieurs images sur ChatGPT, déterminer pourquoi le barbecue ne peut pas démarrer, vérifier quels plats délicieux peuvent être préparés dans le réfrigérateur ou analyser des graphiques complexes pour obtenir des données. Si vous souhaitez que ChatGPT se concentre sur une partie spécifique de l’image, vous pouvez également utiliser les outils de dessin de l’APP pour la mettre en évidence.
Comme on peut le voir dans l’exemple de vidéo fourni par OpenAI, lorsqu’un utilisateur envoie une photo d’un vélo à ChatGPT et demande comment abaisser le tapis, ChatGPT non seulement observera spontanément le modèle de vélo, identifiera les pièces et donnera des étapes détaillées, mais également des instructions, et déterminez si les outils existants de l’utilisateur peuvent faire le travail.
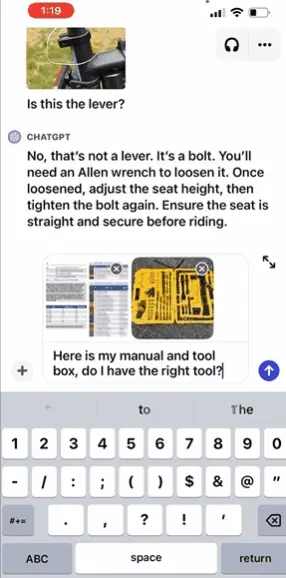 Il est à noter que dans un article publié le même jour, OpenAI a appelé ce modèle capable de visualiser des images GPT-4V(ision)**. Le modèle a terminé sa formation en 2022, avant que l’accès anticipé aux tests ne commence début 2023.
Il est à noter que dans un article publié le même jour, OpenAI a appelé ce modèle capable de visualiser des images GPT-4V(ision)**. Le modèle a terminé sa formation en 2022, avant que l’accès anticipé aux tests ne commence début 2023.
Avec l’aide de GPT-4V, OpenAI a coopéré avec l’organisation Be My Eyes en mars de cette année pour développer Be My AI, qui peut décrire le monde extérieur pour les personnes aveugles et malvoyantes. Des tests ont montré que Be My AI peut fournir à 500 000 utilisateurs aveugles et malvoyants des outils pour répondre à leurs besoins en matière d’information, de culture et d’emploi.
De plus, OpenAI a également testé les capacités de craquage du code de vérification et de géolocalisation de GPT-4V. Le premier a montré que le modèle a la capacité de résoudre des énigmes et d’effectuer des tâches de raisonnement visuel complexes, et le second a montré que le modèle peut rechercher pour les objets/emplacements. Mais ces deux fonctionnalités impliqueront des problèmes de sécurité du réseau et de confidentialité.
Quant à une autre fonction de reconnaissance et de génération vocale dans cette mise à jour, OpenAI a déclaré que les utilisateurs peuvent utiliser cette fonction pour raconter des histoires à leurs enfants au coucher, et peuvent également être utilisés comme aide lors d’une querelle.
OpenAI travaille avec des comédiens professionnels pour fournir 5 voix différentes. De plus, la société s’est également associée à Spotify pour utiliser cette fonctionnalité afin de traduire des podcasts dans d’autres langues tout en conservant la voix de l’hôte du podcast.
 Il convient de mentionner que les données montrent que le trafic ChatGPT a récemment rebondi. Les données de SimilarWeb montrent qu’au cours de la semaine du 11 septembre, le trafic ChatGPT a augmenté d’environ 12 % par rapport à la semaine précédente. Une autre société d’analyse, Sensor Tower, a rapporté que la croissance mondiale des utilisateurs de l’application ChatGPT a dépassé 10 % par semaine au cours des deux dernières semaines d’août. On rapporte que la principale raison de l’augmentation du trafic est le fait que les étudiants ont commencé à retourner à l’école et que les marchés indien et brésilien connaissent une croissance.
Il convient de mentionner que les données montrent que le trafic ChatGPT a récemment rebondi. Les données de SimilarWeb montrent qu’au cours de la semaine du 11 septembre, le trafic ChatGPT a augmenté d’environ 12 % par rapport à la semaine précédente. Une autre société d’analyse, Sensor Tower, a rapporté que la croissance mondiale des utilisateurs de l’application ChatGPT a dépassé 10 % par semaine au cours des deux dernières semaines d’août. On rapporte que la principale raison de l’augmentation du trafic est le fait que les étudiants ont commencé à retourner à l’école et que les marchés indien et brésilien connaissent une croissance.
▌Les grands modèles multimodaux sont devenus un champ de bataille pour les stratèges militaires, et la demande de puissance de calcul a considérablement augmenté
De nos jours, les fonctions multimodales sont devenues incontournables pour les grands modèles d’IA. Meta a récemment lancé AudioCraft, qui génère de la musique grâce à l’IA ; les robots Google Bard et Bing ont déployé des fonctions multimodes ; Apple expérimente également la voix générée par l’IA, Personal Voice.
Avec le développement rapide des capacités de perception, d’interaction et de génération de l’IA, les scénarios d’application et l’écologie devraient encore s’enrichir. La taille des données vocales et image est nettement supérieure à celle du texte. Les courtiers ont souligné que la demande de puissance de calcul de formation et d’inférence pour les grands modèles multimodaux augmentera considérablement.
Par exemple, Gemini, un grand modèle multimodal pour lequel Google fonde de grands espoirs, a commencé à s’entraîner sur le pod TPUv5, selon les analystes de SemiAnalysi Dylan Patel et Daniel Nishball, avec une puissance de calcul allant jusqu’à ~ 1e26 FLOPS, ce qui est nécessaire pour formation GPT-4 5 fois la puissance de calcul**.
Meng Wanzhou, vice-président, président tournant et directeur financier de Huawei, a également déclaré récemment : « La puissance de calcul est la principale force motrice du développement de l’intelligence artificielle. Les grands modèles nécessitent une grande puissance de calcul, et la quantité de puissance de calcul détermine la vitesse d’itération et d’itération de l’IA. " L’innovation, et cela affecte également la vitesse du développement économique. La rareté et le coût de la puissance de calcul sont devenus les principaux facteurs limitant le développement de l’IA. "
Guosen Securities a souligné que les trois éléments de **IA (grand modèle, puissance de calcul et application) favorisent une relation en spirale. Les trois éléments de l’IA vont et viennent dans un cycle de “mise à jour du modèle - itération de la puce de puissance de calcul, réduction du coût unitaire des jetons - augmentation des applications”. Lorsque l’un des trois éléments entre en éruption, c’est une période de forte stimulation ; si les trois éléments ne sont pas mis à jour en même temps, il entrera en stagnation. Période, en attendant la prochaine épidémie.
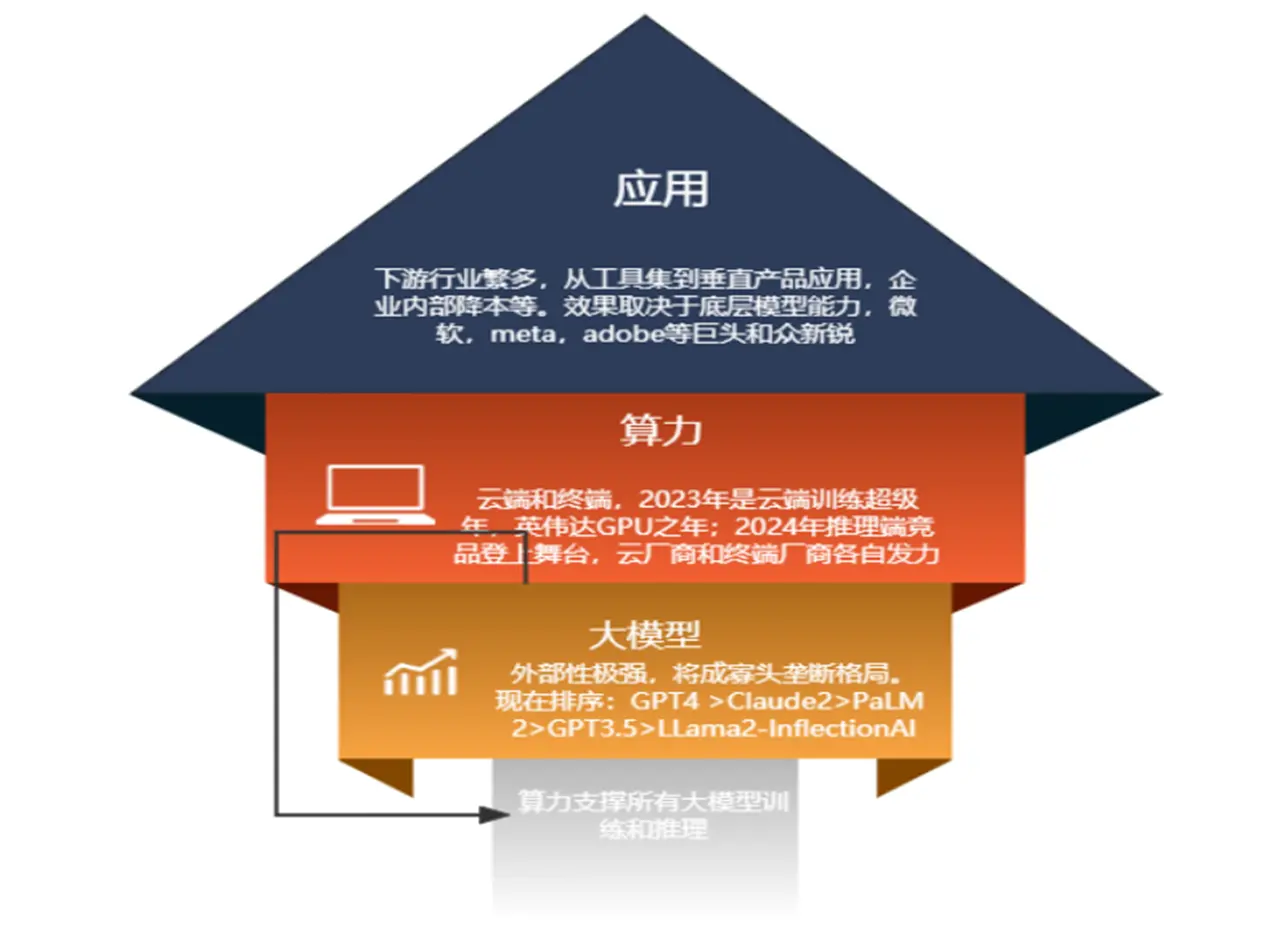 Les grands modèles multimodaux constituent la future tendance de développement. En corrélant différents types de données entre eux, la précision et la robustesse du modèle peuvent être considérablement améliorées et les scénarios d’application peuvent être encore élargis.
Les grands modèles multimodaux constituent la future tendance de développement. En corrélant différents types de données entre eux, la précision et la robustesse du modèle peuvent être considérablement améliorées et les scénarios d’application peuvent être encore élargis.
Parallèlement, en mars, Google a lancé le modèle de langage visuel incorporé (VLM) multimodal PaLM-E, qui peut être utilisé dans le domaine de la robotique ; en juillet, Google a lancé une nouvelle génération de modèle vision-langage-action (VLA). Le modèle Robotics Transformer 2 (RT-2), dédié au domaine de la robotique, est optimiste quant à la tendance des robots autonomes de grand modèle, et les analystes sont optimistes quant à la tendance des robots autonomes de grand modèle**.
Avertissement : Les informations contenues dans cette page peuvent provenir de tiers et ne représentent pas les points de vue ou les opinions de Gate. Le contenu de cette page est fourni à titre de référence uniquement et ne constitue pas un conseil financier, d'investissement ou juridique. Gate ne garantit pas l'exactitude ou l'exhaustivité des informations et n'est pas responsable des pertes résultant de l'utilisation de ces informations. Les investissements en actifs virtuels comportent des risques élevés et sont soumis à une forte volatilité des prix. Vous pouvez perdre la totalité du capital investi. Veuillez comprendre pleinement les risques pertinents et prendre des décisions prudentes en fonction de votre propre situation financière et de votre tolérance au risque. Pour plus de détails, veuillez consulter l'
avertissement.