Source : Qubit
Quand je me suis réveillé pendant la nuit, il y avait un mot brûlant dans le grand cercle des modèles - “GPU-Poor” (GPU-Poor).
Un rapport de SemiAnalysis, une organisation d’analyse industrielle, a révélé que Google dispose de plus de ressources informatiques qu’OpenAI, Meta, Amazon, Oracle et CoreWeave réunis.
L’analyste Dylan Patel prédit que d’ici la fin de l’année, le volume de formation de Gemini, le grand modèle de nouvelle génération développé conjointement par Google DeepMind, écrasera (Smash) GPT-4 de 5 fois.
Le rapport souligne que face à cet avantage écrasant, la plupart des startups et des forces open source sont devenues « pauvres en GPU », aux prises avec des ressources limitées.
Cette déclaration à la fois accrocheuse et déchirante est rapidement devenue un nouveau mème et s’est répandue dans l’industrie.
 Le mème le plus populaire la dernière fois était “pas de douves”. Par coïncidence, il a été créé par le même auteur, et c’est également lui qui a exposé les détails de l’architecture interne de GPT-4.
Le mème le plus populaire la dernière fois était “pas de douves”. Par coïncidence, il a été créé par le même auteur, et c’est également lui qui a exposé les détails de l’architecture interne de GPT-4.
Julien Chaumond, co-fondateur de HuggingFace, leader reconnu de l’open source, a déclaré : Ne nous sous-estimez pas, nous les pauvres.
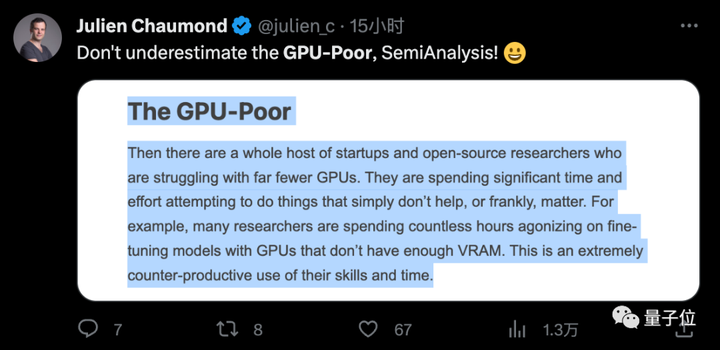 Certains se sont également plaints en ligne au nom des étudiants : nous sommes pauvres en termes d’argent, mais nous sommes également pauvres en termes de puissance de calcul. Nous sommes les doctorants qui en parlons.
Certains se sont également plaints en ligne au nom des étudiants : nous sommes pauvres en termes d’argent, mais nous sommes également pauvres en termes de puissance de calcul. Nous sommes les doctorants qui en parlons.
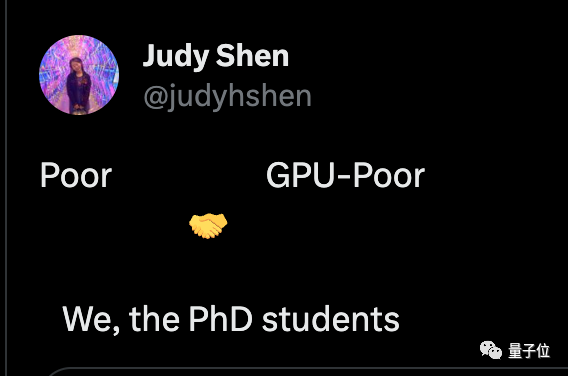 Chen Tianqi, un chercheur bien connu qui travaille à faire fonctionner les téléphones mobiles avec de grands modèles, a déclaré que chacun aura son propre assistant IA à l’avenir, et que la plupart d’entre eux seront « pauvres en GPU », mais ne sous-estimez pas le total. montant.
Chen Tianqi, un chercheur bien connu qui travaille à faire fonctionner les téléphones mobiles avec de grands modèles, a déclaré que chacun aura son propre assistant IA à l’avenir, et que la plupart d’entre eux seront « pauvres en GPU », mais ne sous-estimez pas le total. montant.
 De nombreuses personnes pensent également que, indépendamment du contenu controversé et de la plupart des frais de contenu, l’avant-propos gratuit de ce rapport constitue une bonne critique et un bon résumé de la situation actuelle de l’industrie du modélisme à grande échelle.
De nombreuses personnes pensent également que, indépendamment du contenu controversé et de la plupart des frais de contenu, l’avant-propos gratuit de ce rapport constitue une bonne critique et un bon résumé de la situation actuelle de l’industrie du modélisme à grande échelle.
Les « pauvres en GPU » font un travail inutile
Le rapport est très impitoyable et affirme sans ambages que de nombreuses startups consacrent beaucoup de temps et d’énergie à faire des choses qui sont vaines lorsqu’elles manquent de GPU.
Par exemple, de nombreuses personnes souhaitent utiliser les résultats de grands modèles pour affiner les petits modèles, puis passer à brosser les classements, mais la méthode d’évaluation est imparfaite et se concentre davantage sur le style plutôt que sur la précision ou praticité.
Le rapport estime également que les classements eux-mêmes, avec des normes de mesure imparfaites, sont également trompeurs pour les petites entreprises, ce qui entraîne un grand nombre de modèles peu pratiques, ce qui nuit également au mouvement open source.
D’un autre côté, les personnes pauvres en GPU au lieu d’utiliser les ressources efficacement, la plupart d’entre elles utilisent des modèles intensifs, principalement basés sur l’écologie open source de l’alpaga.
Cependant, des géants tels qu’OpenAI et Google jouent déjà avec des modèles clairsemés** tels que l’architecture MoE et utilisent de petits modèles** d’échantillonnage spéculatif (décodage spéculatif) pour améliorer l’efficacité du raisonnement, complètement deux jeux.
L’auteur espère que les personnes pauvres en GPU ne limiteront pas excessivement la taille du modèle et la quantification excessive, tout en ignorant la dégradation de la qualité du modèle. Il devrait se concentrer sur la fourniture efficace de modèles affinés sur une infrastructure partagée, en réduisant les besoins en matière de latence et de bande passante mémoire pour répondre aux besoins de l’informatique de pointe.
Voyant cela, certaines personnes ont également exprimé des opinions différentes, estimant que les percées créatives proviennent souvent d’environnements restreints, ce qui est en fait un avantage.
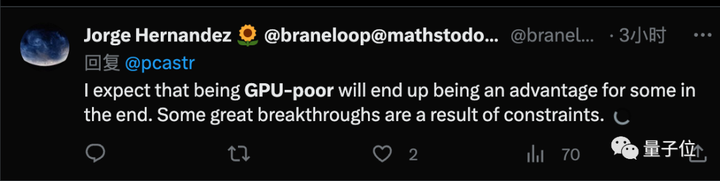 Mais Aravind Srinivas, co-fondateur de Perplexity.AI, estime que les organisations riches en GPU investiront réellement dans la recherche avec des contraintes.
Mais Aravind Srinivas, co-fondateur de Perplexity.AI, estime que les organisations riches en GPU investiront réellement dans la recherche avec des contraintes.
Et pour trouver la prochaine avancée comme Transformer, des milliers d’expériences sont nécessaires, et les ressources requises ne sont certainement pas faibles.

Comment jouer au jeu de “Tyran local GPU”
Alors, que fait l’autre côté des civils du GPU, Google, le « magnat du GPU », ? .
À proprement parler, la puissance de calcul de Google n’est pas le GPU mais son propre TPU. Le rapport estime que même si les performances d’une seule unité du TPUv5 ne sont pas aussi bonnes que celles du NVIDIA H100, Google possède l’architecture d’infrastructure la plus efficace.
Après la fusion de Google Brain et DeepMind, ils ont formé conjointement le modèle Gemini contre GPT-4.
Une équipe de 100 personnes est dirigée conjointement par deux anciens vice-présidents de la recherche DeepMind Koray Kavukcuoglu et Oriol Vinyals et l’ancien responsable de Google Brain Jeff Dean.
 Selon divers rapports, Gemini devrait sortir d’ici ans, plus précisément dans la période d’automne aux États-Unis (23 septembre-21 décembre).
Selon divers rapports, Gemini devrait sortir d’ici ans, plus précisément dans la période d’automne aux États-Unis (23 septembre-21 décembre).
Gemini intégrera les capacités de grands modèles et de génération d’images IA, en utilisant 9,36 milliards de minutes de formation de sous-titres vidéo sur Youtube, et la taille totale de l’ensemble de données est estimée à deux fois celle de GPT-4.
Hassabis, ancien fondateur de DeepMind, a révélé que Gemini combinerait certaines des capacités d’un système de type AlphaGo avec “d’autres innovations très intéressantes”.
De plus, le fondateur de Google, Brin, a été personnellement impliqué dans la recherche et le développement de Gemini, notamment en évaluant le modèle et en aidant à la formation.
Il n’y a pas beaucoup de nouvelles plus spécifiques sur Gemini, mais certaines personnes pensent qu’il utilisera également la même architecture MoE et la même technologie d’échantillonnage spéculatif que GPT-4.
Un nouvel article, From Sparse to Soft Mixtures of Experts, publié par Google DeepMind début août, est considéré comme potentiellement lié à Gemini.
 L’échantillonnage spéculatif peut accélérer l’inférence de 2 à 3 fois pour les grands modèles de Transformer sans perte de qualité de génération.
L’échantillonnage spéculatif peut accélérer l’inférence de 2 à 3 fois pour les grands modèles de Transformer sans perte de qualité de génération.
Plus précisément, laissez le petit modèle générer des jetons à l’avance et laissez le grand modèle porter un jugement. S’il est accepté, laissez le grand modèle générer le jeton suivant et répétez la première étape. Si la qualité du petit modèle n’est pas élevée, puis passez au grand modèle.
L’article d’échantillonnage spéculatif de Google n’a été publié qu’en novembre 2022, mais des rapports précédents suggéraient que GPT-4 utilisait également une technologie similaire.
 En fait, le prédécesseur de la technologie d’échantillonnage spéculatif, Blockwise Parallel Decoding, vient également de Google, et ses auteurs incluent Noam Shazeer, l’un des auteurs de Transformer.
En fait, le prédécesseur de la technologie d’échantillonnage spéculatif, Blockwise Parallel Decoding, vient également de Google, et ses auteurs incluent Noam Shazeer, l’un des auteurs de Transformer.
Lorsqu’il était chez Google, Noam Shazeer a participé aux recherches sur Transformer, MoE et l’échantillonnage spéculatif, qui sont tous cruciaux pour les grands modèles d’aujourd’hui. En outre, il a également participé à la recherche de plusieurs grands modèles tels que T5, LaMDA et PaLM.
Le rapport de SemiAnalysis a également raconté l’un de ses potins.
Dès l’ère GPT-2, Noam Shazeer avait écrit une note interne chez Google, prédisant que les grands modèles seraient intégrés de diverses manières dans la vie des gens à l’avenir, mais ce point de vue n’a pas été pris au sérieux par Google à l’époque.
Il apparaît maintenant que bon nombre des choses qu’il avait prédites se sont réellement produites après la sortie de ChatGPT.
Cependant, Noam Shazeer a quitté Google pour lancer Character.ai en 2021. Selon ce rapport, il fait désormais également partie des « pauvres en GPU ».
Liens de référence :
[1]
[2]
[3]
[4]