Fuente: Qubits
Cuando me desperté durante la noche, había una palabra candente en el gran círculo de modelos: “GPU-Poor” (GPU-Poor).
Un informe de SemiAnalysis, una organización de análisis de la industria, reveló que Google tiene más recursos informáticos que OpenAI, Meta, Amazon, Oracle y CoreWeave juntos.
El analista Dylan Patel predice que para finales de año, el modelo Gemini a gran escala de próxima generación desarrollado conjuntamente por Google DeepMind aplastará (Smash) GPT-4 para alcanzar 5 veces este último.
El informe señala que frente a esta abrumadora ventaja, la mayoría de las empresas emergentes y las fuerzas de código abierto se han vuelto “pobres en GPU” y luchan con recursos limitados.
Esta declaración llamativa y desgarradora rápidamente se convirtió en un nuevo meme y se extendió en la industria.
 El meme más popular la última vez fue “sin foso”. Casualmente fue creado por el mismo autor, y él también fue quien expuso los detalles de la arquitectura interna de GPT-4.
El meme más popular la última vez fue “sin foso”. Casualmente fue creado por el mismo autor, y él también fue quien expuso los detalles de la arquitectura interna de GPT-4.
Julien Chaumond, cofundador de HuggingFace, el líder del código abierto, dijo: No nos subestimen a los pobres.
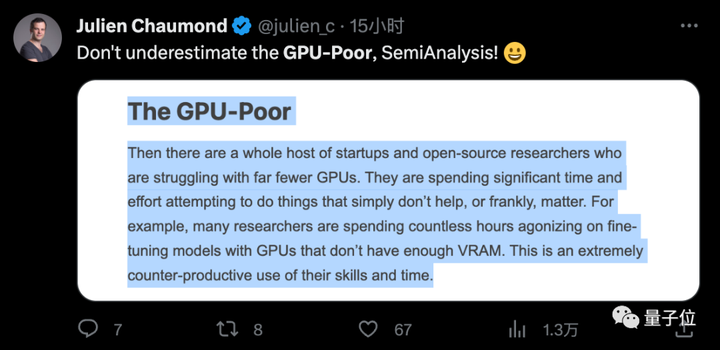 Algunas personas también se quejaron en línea en nombre de los estudiantes: somos pobres en dinero y pobres en potencia informática, y hablan de nosotros, estudiantes de doctorado.
Algunas personas también se quejaron en línea en nombre de los estudiantes: somos pobres en dinero y pobres en potencia informática, y hablan de nosotros, estudiantes de doctorado.
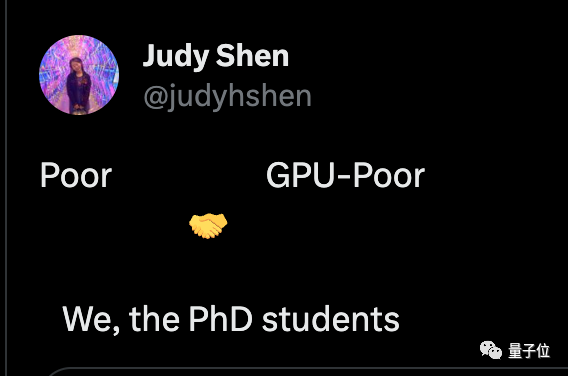 Chen Tianqi, un conocido académico que está trabajando para hacer que los teléfonos móviles funcionen con modelos grandes, dijo que todos tendrán su propio asistente de inteligencia artificial en el futuro y que la mayoría de ellos serán “pobres en GPU”, pero no subestimen el total. cantidad.
Chen Tianqi, un conocido académico que está trabajando para hacer que los teléfonos móviles funcionen con modelos grandes, dijo que todos tendrán su propio asistente de inteligencia artificial en el futuro y que la mayoría de ellos serán “pobres en GPU”, pero no subestimen el total. cantidad.
 Mucha gente también cree que, independientemente del contenido controvertido y de los cargos por la mayor parte del contenido, el prefacio gratuito de este informe es una buena crítica y un resumen de la situación actual de la gran industria del modelismo.
Mucha gente también cree que, independientemente del contenido controvertido y de los cargos por la mayor parte del contenido, el prefacio gratuito de este informe es una buena crítica y un resumen de la situación actual de la gran industria del modelismo.
Los “pobres en GPU” están haciendo un trabajo inútil
El informe es muy despiadado y afirma sin rodeos que muchas empresas emergentes dedican mucho tiempo y energía a hacer cosas que son en vano cuando les faltan GPU.
Por ejemplo, muchas personas están interesadas en utilizar el resultado del modelo grande para ajustar el modelo pequeño y luego ir a barrer la tabla de clasificación, pero el método de evaluación no es perfecto y presta más atención a estilo que precisión o practicidad.
El informe también cree que la clasificación en sí con varios estándares de medición también es engañosa para las pequeñas empresas, lo que da como resultado una gran cantidad de modelos poco prácticos, lo que es también una especie de daño para el movimiento de código abierto.
Por otro lado, las personas pobres en GPU en lugar de utilizar los recursos de manera eficiente, la mayoría utiliza modelos intensivos, basados principalmente en la ecología de la alpaca de código abierto.
Pero gigantes como OpenAI y Google ya están jugando con modelos dispersos** como la arquitectura MoE, y utilizando modelos pequeños** de muestreo especulativo (decodificación especulativa) para mejorar la eficiencia del razonamiento, que son dos juegos completamente diferentes**.
El autor espera que los pobres en GPU no limiten excesivamente el tamaño del modelo y la cuantificación excesiva, ignorando la degradación de la calidad del modelo. Debería centrarse en ofrecer de manera eficiente modelos optimizados en infraestructura compartida, reduciendo la latencia y los requisitos de ancho de banda de memoria para satisfacer las necesidades de la informática de punta.
Al ver esto, algunas personas también expresaron opiniones diferentes, creyendo que los avances creativos a menudo provienen de entornos restringidos, lo que en realidad es una ventaja.
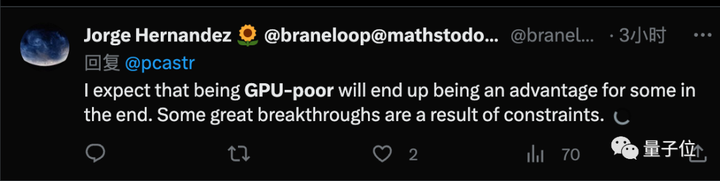 Pero el cofundador de Perplexity.AI, Aravind Srinivas, cree que las organizaciones ricas en GPU en realidad invertirán en investigación con limitaciones.
Pero el cofundador de Perplexity.AI, Aravind Srinivas, cree que las organizaciones ricas en GPU en realidad invertirán en investigación con limitaciones.
Y para encontrar el próximo avance como Transformer, se requieren miles de experimentos y los recursos necesarios definitivamente no son bajos.

Cómo jugar el juego del “tirano local de GPU”
Entonces, del otro lado de los civiles de la GPU, ¿qué está haciendo Google, el “tirano local de la GPU”? .
Estrictamente hablando, la potencia informática de Google no es la GPU sino su propia TPU. El informe cree que aunque el rendimiento de una sola unidad de TPUv5 no es tan bueno como el de NVIDIA H100, Google tiene la arquitectura de infraestructura más eficiente.
Después de la fusión de Google Brain y DeepMind, entrenaron conjuntamente el modelo Gemini contra GPT-4.
Un equipo de 100 personas está liderado conjuntamente por dos ex vicepresidentes de investigación de DeepMind Koray Kavukcuoglu y Oriol Vinyals y el ex director de Google Brain Jeff Dean.
 Según diversas fuentes, se espera que Gemini lance el producto dentro de ** año, más exactamente, dentro del rango de otoño en los Estados Unidos (del 23 de septiembre al 21 de diciembre).
Según diversas fuentes, se espera que Gemini lance el producto dentro de ** año, más exactamente, dentro del rango de otoño en los Estados Unidos (del 23 de septiembre al 21 de diciembre).
Gemini integrará modelos grandes con capacidades de generación de imágenes de IA y utilizará 9,36 mil millones de minutos de entrenamiento de subtítulos de video en Youtube. Se estima que el tamaño total del conjunto de datos será el doble que el de GPT-4.
El exfundador de DeepMind, Hassabis, ha revelado que Gemini combinará algunas capacidades de los sistemas tipo AlphaGo con “otras innovaciones muy interesantes”.
Además, el fundador de Google, Brin, ha participado personalmente en la investigación y el desarrollo de Gemini, incluida la evaluación del modelo y la asistencia en la capacitación.
No hay muchas noticias más específicas sobre Gemini, pero algunas personas especulan que también utilizará arquitectura MoE y tecnología de muestreo especulativo como GPT-4.
Se considera que un nuevo artículo, From Sparse to Soft Mixtures of Experts publicado por Google DeepMind a principios de agosto, está posiblemente relacionado con Gemini.
 El muestreo especulativo puede proporcionar a los modelos grandes de Transformer una inferencia 2 o 3 veces más rápida sin pérdida de calidad de generación.
El muestreo especulativo puede proporcionar a los modelos grandes de Transformer una inferencia 2 o 3 veces más rápida sin pérdida de calidad de generación.
Específicamente, deje que el modelo pequeño genere algunos tokens por adelantado y deje que el modelo grande juzgue. Si es aceptado, deje que el modelo grande genere el siguiente token y repita el primer paso. Si la calidad generada por el modelo pequeño no es alta , cambie al modelo grande.
El documento de muestreo especulativo de Google no se publicará hasta noviembre de 2022, pero revelaciones anteriores sugieren que GPT-4 también utiliza tecnología similar.
 De hecho, el predecesor de la tecnología de muestreo especulativo, Blockwise Parallel Decoding, también proviene de Google, y entre sus autores se encuentra Noam Shazeer, uno de los autores de Transformer.
De hecho, el predecesor de la tecnología de muestreo especulativo, Blockwise Parallel Decoding, también proviene de Google, y entre sus autores se encuentra Noam Shazeer, uno de los autores de Transformer.
Noam Shazeer participó en la investigación de Transformer, MoE y muestreo especulativo cuando estaba en Google, que son cruciales para los grandes modelos actuales. Además, también participó en la investigación de múltiples modelos grandes como T5, LaMDA y PaLM.
El informe de SemiAnálisis también contó un chisme sobre él.
Ya en la era GPT-2, Noam Shazeer escribió un memorando interno en Google, prediciendo que modelos grandes se integrarían en la vida de las personas de diversas maneras en el futuro, pero Google no tomó en serio esta opinión en ese momento.
Ahora parece que muchas de las cosas que predijo realmente sucedieron después del lanzamiento de ChatGPT.
Sin embargo, Noam Shazeer dejó Google para iniciar Character.ai en 2021. Según este informe, ahora también forma parte de los “pobres de GPU”.
Enlaces de referencia:
[1]
[2]
[3]
[4]
