Escrito por Jay : : FP
Compilación: Deep Tide TechFlow
La publicación del libro blanco de Bitcoin en 2008 provocó un replanteamiento del concepto de confianza. Blockchain luego amplió su definición para incluir la noción de un sistema sin confianza y evolucionó rápidamente para argumentar que diferentes tipos de valor, como la soberanía individual, la democratización financiera y la propiedad, podrían aplicarse a los sistemas existentes. Por supuesto, es posible que se requiera mucha validación y discusión antes de que blockchain pueda usarse en la práctica, porque sus características pueden parecer algo radicales en comparación con varios sistemas existentes. Sin embargo, si somos optimistas sobre estos escenarios, la construcción de canalizaciones de datos y el análisis de la valiosa información contenida en el almacenamiento de la cadena de bloques tiene el potencial de convertirse en otro importante punto de inflexión en el desarrollo de la industria, porque podemos observar una Web3 que nunca antes existió. inteligencia.
Este documento explora el potencial de las canalizaciones de datos nativas de Web3 mediante la proyección de canalizaciones de datos comúnmente utilizadas en los mercados de TI existentes en un entorno Web3. El artículo analiza los beneficios de estos oleoductos, los desafíos que deben abordarse y el impacto de estos oleoductos en la industria.
1. La singularidad proviene de la innovación de la información
“El lenguaje es una de las diferencias más importantes entre los humanos y los animales inferiores. No es solo la capacidad de emitir sonidos, sino de asociar sonidos definidos con pensamientos definidos y usar esos sonidos como símbolos para la comunicación de ideas”.
Históricamente, los principales avances en la civilización humana han ido acompañados de innovaciones en el intercambio de información. Nuestros antepasados usaban el lenguaje, tanto hablado como escrito, para comunicarse entre sí y transmitir conocimientos a las generaciones futuras. Esto les da una gran ventaja sobre otras especies. La invención de la escritura, el papel y la imprenta hizo posible compartir información más ampliamente, lo que condujo a importantes avances en la ciencia, la tecnología y la cultura. La impresión de tipos móviles de metal de la Biblia de Gutenberg en particular fue un momento decisivo, ya que hizo posible la producción en masa de libros y otros materiales impresos. Esto tuvo un profundo impacto en los inicios de la Reforma, la Revolución Democrática y el progreso científico.
El rápido desarrollo de la tecnología de TI en la década de 2000 nos permitió obtener una comprensión más profunda del comportamiento humano. Esto ha llevado a un cambio en el estilo de vida en el que la mayoría de las personas en los tiempos modernos toman varias decisiones basadas en información digital. Es por esta razón que nos referimos a la sociedad moderna como la “Era de la innovación de TI”.
Solo 20 años después de la comercialización total de Internet, la tecnología de inteligencia artificial ha vuelto a asombrar al mundo. Hay muchas aplicaciones que pueden reemplazar el trabajo humano, y muchas personas están discutiendo la civilización que cambiará la IA. Algunos incluso lo niegan y se preguntan cómo una tecnología así podría surgir tan rápido como para sacudir los cimientos de nuestra sociedad. Aunque existe la “Ley de Moore” que muestra que el rendimiento de los semiconductores aumentará exponencialmente con el tiempo, los cambios provocados por la aparición de GPT son demasiado repentinos para enfrentarlos de inmediato.
Curiosamente, sin embargo, el modelo GPT en sí mismo no es en realidad una arquitectura muy innovadora. Por otro lado, la industria de IA enumerará los siguientes como los principales factores de éxito para los modelos GPT: 1) Definición de dominios comerciales que pueden dirigirse a grandes grupos de clientes, y 2) Ajuste del modelo a través de canalizaciones de datos, desde la adquisición de datos hasta el final. resultados y retroalimentación basada en resultados de. En resumen, estas aplicaciones permiten la innovación al perfeccionar los propósitos de prestación de servicios y mejorar los procesos de procesamiento de datos/información.
2. Las decisiones basadas en datos están en todas partes
La mayor parte de lo que llamamos innovación se basa en realidad en la manipulación de datos acumulados, no en el azar o la intuición. Como dice el refrán, “En un mercado capitalista, no son los fuertes los que sobreviven, sino los sobrevivientes los que son fuertes”. Las empresas de hoy son altamente competitivas y el mercado está saturado. Por lo tanto, las empresas recopilan y analizan todo tipo de datos para captar incluso el nicho más pequeño.
Puede que estemos demasiado obsesionados con la teoría de la “destrucción creativa” de Schumpeter y demasiado énfasis en tomar decisiones basadas en la intuición. Sin embargo, incluso una gran intuición es, en última instancia, el producto de los datos y la información acumulados por un individuo. El mundo digital penetrará más profundamente en nuestras vidas en el futuro, y se presentará cada vez más información confidencial en forma de datos digitales.
El mercado Web3 está recibiendo mucha atención por su potencial para dar a los usuarios control sobre sus datos. Sin embargo, el campo blockchain, que es la tecnología básica de Web3, actualmente está más preocupado por resolver el trilema (Deep Tide Note: Triangular Dilemma, es decir, problemas de seguridad, descentralización y escalabilidad). Para que las nuevas tecnologías sean convincentes en el mundo real, es importante desarrollar aplicaciones e inteligencia que se puedan utilizar de múltiples maneras. Hemos visto que esto sucede en el espacio de Big Data, y las metodologías para construir el procesamiento de Big Data y las canalizaciones de datos han avanzado significativamente desde alrededor de 2010. En el contexto de Web3, se deben hacer esfuerzos para hacer avanzar la industria y construir sistemas de flujo de datos para generar inteligencia basada en datos.
3. Oportunidades basadas en flujo de datos en la cadena
Entonces, ¿qué oportunidades podemos capturar de los sistemas de transmisión nativos de Web3 y qué desafíos debemos abordar para aprovechar estas oportunidades?
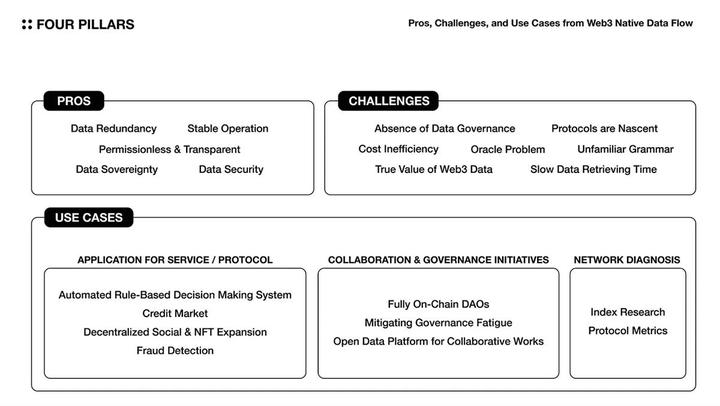
3.1 Ventajas
En resumen, el valor de configurar flujos de datos nativos de Web3 es que los datos confiables se pueden distribuir de manera segura y eficiente a múltiples entidades para que se puedan extraer conocimientos valiosos.
- Redundancia de datos: es menos probable que se pierdan los datos en cadena y son más resistentes porque la red de protocolo almacena fragmentos de datos en múltiples nodos.
- Seguridad de datos: los datos en cadena son a prueba de manipulaciones, ya que son verificados y consensuados por una red de nodos descentralizados.
- Soberanía de datos: la soberanía de datos es el derecho de los usuarios a poseer y controlar sus propios datos. Con la transmisión de datos en cadena, los usuarios pueden ver cómo se utilizan sus datos y elegir compartirlos solo con aquellos que tienen una necesidad legítima de acceder a ellos.
- Sin permiso y transparente: los datos en cadena son transparentes y a prueba de manipulaciones. Esto asegura que los datos que se procesan también sean una fuente confiable de información.
- Operación estable: cuando el flujo de datos está orquestado por el protocolo en un entorno distribuido, dado que no hay un punto único de falla, la probabilidad de que cada capa esté expuesta a tiempo de inactividad se reduce significativamente.
3.2 Casos de aplicación
La confianza es la base para que diferentes entidades interactúen entre sí y tomen decisiones. Por lo tanto, cuando se pueden distribuir datos confiables de manera segura, significa que se pueden tomar muchas interacciones y decisiones a través de los servicios Web3 en los que participan varias entidades. Esto ayuda a maximizar el capital social, y podemos imaginar varios casos de uso a continuación.
3.2.1 Servicio/Aplicación de Protocolo
Sistema de decisiones automatizado basado en reglas: los protocolos utilizan parámetros clave para ejecutar servicios. Estos parámetros se ajustan periódicamente para estabilizar el estado del servicio y brindar a los usuarios la mejor experiencia. Sin embargo, el protocolo no siempre puede monitorear el estado del servicio y realizar cambios dinámicos en los parámetros de manera oportuna. Esto es lo que hace el flujo de datos en cadena. Los flujos de datos en cadena se pueden usar para analizar el estado del servicio en tiempo real y sugerir el mejor conjunto de parámetros para cumplir con los requisitos del servicio (por ejemplo, aplicar un mecanismo automático de tasa flotante para un protocolo de préstamo).
- Crecimiento del mercado crediticio: el crédito se ha utilizado tradicionalmente en los mercados financieros como una medida de la capacidad de pago de una persona. Esto ayuda a mejorar la eficiencia del mercado. Sin embargo, la definición de crédito sigue sin estar clara en el mercado Web3. Esto se debe a la escasez de datos personales y la falta de gobernanza de datos en todas las industrias. Por lo tanto, se vuelve difícil integrar y recopilar información. Al crear un proceso para recopilar y procesar datos fragmentados en cadena, es posible redefinir el mercado crediticio en el mercado Web3 (por ejemplo, la puntuación MACRO (oráculo de riesgo crediticio de activos múltiples) de Spectral).
- Extensiones sociales/NFT descentralizadas: las sociedades descentralizadas priorizan el control del usuario, la protección de la privacidad, la resistencia a la censura y la gobernanza comunitaria. Esto proporciona un paradigma social alternativo. Por lo tanto, se puede establecer una tubería para controlar y actualizar varios metadatos de manera más fluida y facilitar la migración entre plataformas.
- Detección de fraude: los servicios Web3 que utilizan contratos inteligentes son vulnerables a ataques maliciosos que pueden robar fondos, comprometer sistemas y provocar ataques de desacoplamiento y liquidez. Al crear un sistema que pueda detectar estos ataques con anticipación, los servicios de Web3 pueden desarrollar planes de respuesta rápida y proteger a los usuarios de daños.
3.2.2 Iniciativas de colaboración y gobernanza
- DAO completamente en cadena: las organizaciones autónomas descentralizadas (DAO) dependen en gran medida de herramientas fuera de la cadena para una gobernanza eficiente y financiación pública. Al construir un proceso de procesamiento de datos en cadena y crear un proceso transparente para las operaciones DAO, el valor del DAO nativo de Web3 se puede mejorar aún más.
- Aliviar la fatiga del gobierno: las decisiones del protocolo Web3 a menudo se toman a través del gobierno de la comunidad. Sin embargo, hay muchos factores que pueden dificultar que los participantes participen en la gobernanza, como las barreras geográficas, la presión de monitoreo, la falta de experiencia requerida para la gobernanza, la agenda de gobernanza publicada al azar y la experiencia del usuario inconveniente. Un marco de gobernanza de protocolo podría operar de manera más eficiente y efectiva si se pudiera crear una herramienta que simplifique el proceso para que los participantes pasen de comprender a implementar realmente los elementos individuales de la agenda de gobernanza.
- Plataformas de datos abiertos para trabajos colaborativos: en los círculos académicos e industriales existentes, muchos datos y materiales de investigación no se divulgan públicamente, lo que puede hacer que el desarrollo general del mercado sea muy ineficiente. Por otro lado, los grupos de datos en cadena pueden facilitar más iniciativas de colaboración que los mercados existentes porque son transparentes y accesibles para todos. El desarrollo de muchos estándares de tokens y soluciones DeFi son buenos ejemplos. Además, podemos operar grupos de datos públicos para diversos fines.
3.2.3 Diagnóstico de red
- Index Research: los usuarios de Web3 crean varios indicadores para analizar y comparar el estado del protocolo. Múltiples métricas objetivas (por ejemplo, el coeficiente de Satoshi de Nakaflow) se pueden estudiar y mostrar en tiempo real.
- Métricas de protocolo: al analizar datos como la cantidad de direcciones activas, la cantidad de transacciones, el flujo de entrada/salida de activos y las tarifas incurridas por la red, se puede analizar el rendimiento del protocolo. Esta información se puede utilizar para evaluar el impacto de las actualizaciones de protocolos específicos, el estado de los MEV y el estado de la red.
3.3 Desafíos
Los datos en cadena tienen ventajas únicas que pueden aumentar el valor de la industria. Sin embargo, para aprovechar plenamente estos beneficios, se deben abordar muchos desafíos tanto dentro como fuera de la industria.
- Falta de gobernanza de datos: la gobernanza de datos es el proceso de establecer políticas y estándares de datos coherentes y compartidos para facilitar la integración de cada primitivo de datos. Actualmente, cada protocolo en cadena establece sus propios estándares y recupera sus propios tipos de datos. Sin embargo, el problema es la falta de gobernanza de datos entre las entidades que agregan estos datos de protocolo y brindan servicios de API a los usuarios. Esto dificulta la integración entre servicios y, como resultado, es difícil para los usuarios obtener información confiable y completa.
- Ineficiencia de costos: el almacenamiento de datos en frío en el protocolo ahorra a los usuarios la seguridad de los datos y los costos del servidor. Sin embargo, si es necesario acceder a los datos con frecuencia para su análisis o si se requieren recursos informáticos significativos, es posible que no sea rentable almacenarlos en la cadena de bloques.
- El problema del oráculo: los contratos inteligentes solo son completamente funcionales cuando tienen acceso a datos del mundo real. Sin embargo, estos datos no siempre son confiables o consistentes. A diferencia de las cadenas de bloques, que mantienen la integridad a través de algoritmos de consenso, los datos externos no son deterministas. Las soluciones de Oracle deben evolucionar para garantizar la integridad, la calidad y la escalabilidad de los datos externos independientemente de una capa de aplicación específica.
- El protocolo está en su infancia: el protocolo utiliza su propio token para incentivar a los usuarios a mantener el servicio en funcionamiento y pagarlo. Sin embargo, los parámetros requeridos para operar el protocolo (por ejemplo, la definición precisa y el esquema de incentivos de los usuarios del servicio) a menudo se manejan de manera ingenua. Esto significa que la sostenibilidad económica del protocolo es difícil de verificar. Si muchos protocolos se conectan orgánicamente y crean canalizaciones de datos, habrá una mayor incertidumbre sobre si las canalizaciones funcionarán bien.
- Tiempo de recuperación de datos lento: los protocolos generalmente procesan transacciones a través del consenso de muchos nodos, lo que limita la velocidad y el volumen del procesamiento de información en comparación con la lógica empresarial de TI tradicional. Este cuello de botella es difícil de resolver a menos que se mejore significativamente el rendimiento de todos los protocolos que componen la canalización.
- El valor real de los datos de Web3: las cadenas de bloques son sistemas aislados que aún no están conectados con el mundo real. Al recopilar datos de Web3, debemos considerar si los datos recopilados pueden proporcionar información significativa suficiente para cubrir el costo de construir la canalización de datos.
- Sintaxis desconocida: la infraestructura de datos de TI existente y la infraestructura de cadena de bloques funcionan de manera muy diferente. Incluso el lenguaje de programación utilizado es diferente, y la infraestructura de la cadena de bloques suele utilizar lenguajes de bajo nivel o nuevos lenguajes diseñados específicamente para las necesidades de la cadena de bloques. Esto dificulta que los nuevos desarrolladores y usuarios de servicios aprendan a manejar cada primitivo de datos, ya que necesitan aprender un nuevo lenguaje de programación o una nueva forma de pensar sobre cómo trabajar con datos de blockchain.
4. Datos de Web3 canalizados Lego
No hay conexiones entre las primitivas de datos Web3 actuales, extraen y procesan los datos de forma independiente. Esto dificulta la experimentación de sinergias en el procesamiento de la información. Para abordar este problema, este documento presenta una canalización de datos comúnmente utilizada en el mercado de TI y mapea primitivas de datos Web3 existentes en esta canalización. Esto hará que el caso de uso sea más específico.
4.1 Canalización de datos generales
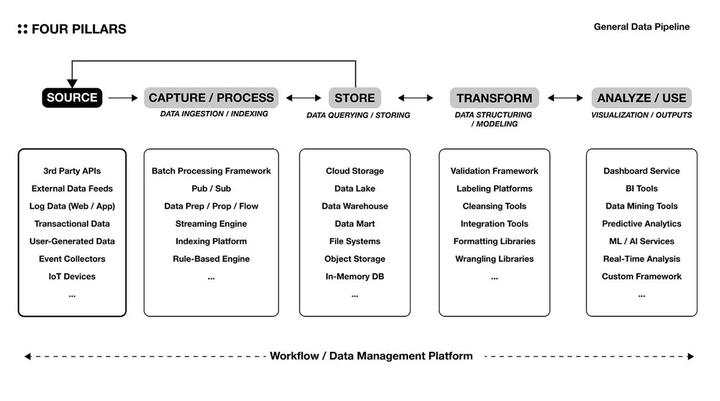
Construir una canalización de datos es como el proceso de conceptualizar y automatizar procesos repetitivos de toma de decisiones en la vida cotidiana. Al hacerlo, la información de una calidad específica está fácilmente disponible y se utiliza para la toma de decisiones. Cuantos más datos no estructurados se procesen, más frecuentemente se utilice la información o más análisis en tiempo real se requiera, el tiempo y el costo de obtener la proactividad necesaria para decisiones futuras se pueden ahorrar mediante la automatización de estos procesos.
El diagrama anterior muestra una arquitectura común para construir canalizaciones de datos en el mercado de infraestructura de TI existente. Los datos adecuados para fines analíticos se recopilan de la fuente de datos correcta y se almacenan en una solución de almacenamiento adecuada según la naturaleza de los datos y los requisitos analíticos. Por ejemplo, los lagos de datos brindan soluciones de almacenamiento de datos sin procesar para un análisis escalable y flexible, mientras que los almacenes de datos se enfocan en almacenar datos estructurados para consultas y análisis optimizados para una lógica comercial específica. Luego, los datos se procesan para obtener conocimientos o información útil de varias maneras.
Cada nivel de solución también está disponible como un servicio empaquetado. También hay un interés creciente en los grupos de productos SaaS ETL (extracción, transformación, carga) que conectan la cadena de procesos desde la extracción de datos hasta la carga (por ejemplo, FiveTran, Panoply, Hivo, Rivery). La secuencia no siempre es unidireccional y las capas se pueden conectar entre sí de diversas formas, según las necesidades específicas de la organización. Lo más importante al crear una canalización de datos es minimizar el riesgo de pérdida de datos que puede ocurrir a medida que se envían y reciben datos en cada nivel de servidor. Esto se puede lograr optimizando el desacoplamiento de servidores y utilizando soluciones confiables de procesamiento y almacenamiento de datos.
4.2 Pipeline con entorno en cadena
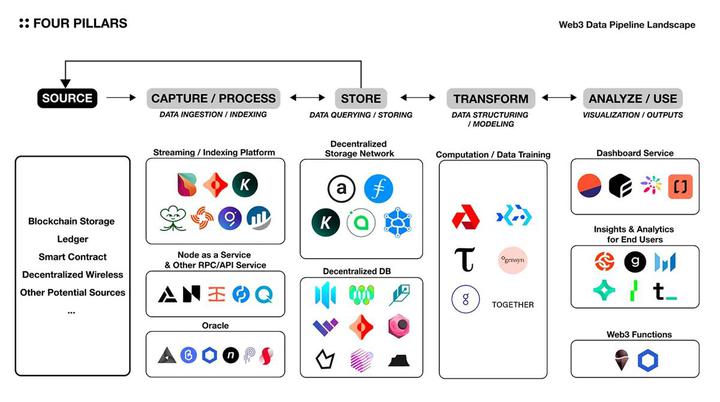
El diagrama conceptual de la tubería de datos presentado anteriormente se puede aplicar al entorno en cadena, como se muestra en la figura anterior, pero se debe tener en cuenta que no se puede formar una tubería completamente descentralizada, porque cada componente básico depende en cierta medida de la Solución centralizada fuera de la cadena. Además, la figura anterior no incluye actualmente todas las soluciones de Web3, y los límites de la clasificación pueden ser borrosos; por ejemplo, KYVE, además de servir como una plataforma de transmisión de medios, también incluye la función de un lago de datos, que puede ser considerado como un conducto de datos en sí mismo. Además, Space and Time se clasifica como una base de datos descentralizada, pero ofrece servicios de puerta de enlace API como RestAPI y transmisión, así como servicios ETL.
4.2.1 Captura/Procesamiento
Para que los usuarios comunes o las dApps consuman u operen los servicios de manera eficiente, deben poder identificar y acceder fácilmente a las fuentes de datos generadas principalmente dentro del protocolo, como transacciones, estado y eventos de registro. Esta capa es donde entra en juego un middleware, que ayuda con procesos que incluyen oráculos, mensajería, autenticación y administración de API. Las principales soluciones son las siguientes.
Plataforma de transmisión/indexación
Bitquery, Ceramic, KYVE, Lens, Streamr Network, The Graph, exploradores de bloques de varios protocolos, etc.
nodo como servicio y otros servicios RPC/API
Alquimia, Todo ese nodo, Infura, Red de bolsillo, Quicknode 等。
Oráculo
API 3, Band Protocol, Chainlink, Nest Protocol, Pyth, Supra Oracles, etc.
4.2.2 Almacenamiento
En comparación con las soluciones de almacenamiento Web2, las soluciones de almacenamiento Web3 tienen varias ventajas, como la persistencia y la descentralización. Sin embargo, también tienen algunas desventajas, como el alto costo, la dificultad en la actualización y consulta de datos. Como resultado, han surgido varias soluciones para abordar estas deficiencias y permitir el procesamiento eficiente de datos estructurados y dinámicos en Web3, cada una con diferentes características, como el tipo de datos procesados, si están estructurados y con función de consulta integrada, etc. en.
Red de almacenamiento descentralizada
Arweave, Filecoin, KYVE, Sia, Storj, etc.
Base de datos descentralizada
Bases de datos basadas en Arweave (Glacier, HollowDB, Kwil, WeaveDB), ComposeDB, OrbitDB, Polybase, Space and Time, Tableland, etc.
* Cada protocolo tiene un mecanismo de almacenamiento permanente diferente. Por ejemplo, Arweave es un modelo basado en blockchain, similar al almacenamiento Ethereum, que almacena datos permanentemente en la cadena, mientras que Filecoin, Sia y Storj son modelos basados en contratos, que almacenan datos fuera de la cadena.
4.2.3 Conversión
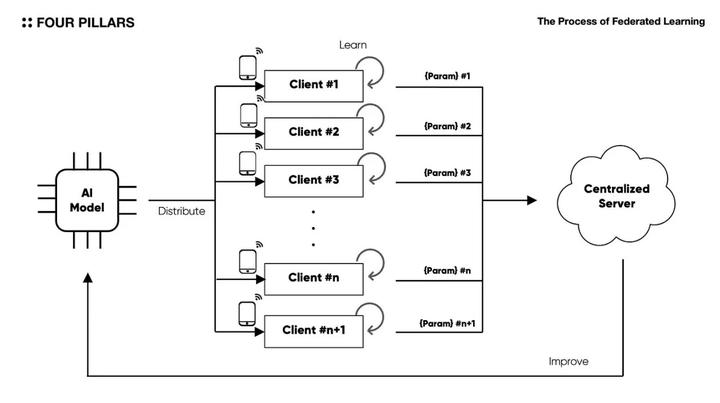
En el contexto de Web3, la capa de traducción es tan importante como la capa de almacenamiento. Esto se debe a que la estructura de la cadena de bloques consiste básicamente en una colección distribuida de nodos, lo que facilita el uso de una lógica de back-end escalable. En la industria de la IA, las personas están explorando activamente el uso de estas ventajas para la investigación en el campo del aprendizaje federado, y han surgido protocolos dedicados al aprendizaje automático y las operaciones de IA.
Entrenamiento/modelado/cálculo de datos
Akash, Bacalhau, Bitensor, Gensyn, Golem, Juntos 等。
* El aprendizaje federado es un método para entrenar modelos de inteligencia artificial al distribuir el modelo original en múltiples clientes nativos, usar datos almacenados para entrenarlo y luego recopilar los parámetros aprendidos en un servidor central.
4.2.4 Análisis/Uso
Los servicios de panel y las soluciones de análisis e información del usuario final que se enumeran a continuación son plataformas que permiten a los usuarios observar y descubrir diversas ideas de protocolos específicos. Algunas de estas soluciones también brindan servicios API al producto final. Sin embargo, es importante tener en cuenta que los datos de estas soluciones no siempre son precisos, ya que en su mayoría utilizan herramientas separadas fuera de la cadena para almacenar y procesar los datos. También se pueden observar errores entre soluciones.
Al mismo tiempo, existe una plataforma llamada “Funciones Web3” que puede activar/activar automáticamente la ejecución de contratos inteligentes, al igual que las plataformas centralizadas como Google Cloud activan/ejecutan una lógica comercial específica. Con esta plataforma, los usuarios pueden implementar la lógica comercial de forma nativa en Web3, en lugar de solo procesar datos en cadena para obtener información.
Servicios de panel
Dune Analytics、Flipside Crypto、Footprint、Transpose 等。
Perspectivas y análisis del usuario final
Chainalaysis, Glassnode, Messari, Nansen, The Tie, Token Terminal, etc.
Funciones Web3
Funciones de Chainlink, Gelato Network, etc.
5. Pensamientos finales

Como dijo Kant, solo podemos presenciar la apariencia de las cosas, pero no su esencia. Sin embargo, usamos registros de observaciones llamados “datos” para procesar información y conocimiento, y vemos cómo las innovaciones en la tecnología de la información impulsan el desarrollo de la civilización. Por lo tanto, la construcción de una canalización de datos en el mercado de Web3, además de estar descentralizada, puede desempeñar un papel clave como punto de partida para capturar realmente estas oportunidades. Me gustaría concluir este artículo con algunas reflexiones.
5.1 El papel de las soluciones de almacenamiento será más importante
El requisito previo más importante para tener una canalización de datos es establecer la gobernanza de datos y API. En un ecosistema cada vez más diverso, las especificaciones creadas por cada protocolo seguirán recreándose, y los registros de transacciones fragmentados a través de ecosistemas de cadenas múltiples dificultarán que las personas obtengan información integral. Entonces, las “soluciones de almacenamiento” son entidades que pueden proporcionar datos integrados en un formato unificado mediante la recopilación de información fragmentada y la actualización de las especificaciones de cada protocolo. Observamos que las soluciones de almacenamiento de mercado existentes, como Snowflake y Databricks, están creciendo rápidamente, tienen una gran base de clientes, están integradas verticalmente al operar en varios niveles en la tubería y están liderando la industria.
5.2 Oportunidades en el mercado de fuentes de datos
Los casos de uso exitosos comenzaron a surgir cuando los datos se volvieron más accesibles y mejoró el procesamiento. Esto crea un efecto circular positivo en el que explotan las fuentes de datos y las herramientas de recopilación: desde 2010, los tipos y volúmenes de datos digitales recopilados cada año han crecido exponencialmente desde 2010, gracias a los enormes avances en tecnología para construir canalizaciones de datos. Aplicando estos antecedentes al mercado Web3, muchas fuentes de datos pueden generarse recursivamente en la cadena en el futuro. Esto también significa que blockchain se expandirá a varios campos comerciales. En este punto, podemos esperar que la adquisición de datos avance a través de mercados de datos como Ocean Protocol o soluciones DeWi (inalámbrica descentralizada) como Helium y XNET, así como soluciones de almacenamiento.
5.3 Lo importante son los datos y el análisis significativos
Sin embargo, lo más importante es seguir preguntándose qué datos se deben preparar para extraer los insights que realmente se necesitan. No hay nada más derrochador que construir una canalización de datos por construir una canalización de datos sin suposiciones explícitas para validar. Los mercados existentes han logrado numerosas innovaciones a través de la construcción de canalizaciones de datos, pero también han pagado un precio incalculable a través de repetidos fracasos sin sentido. También es bueno tener discusiones constructivas sobre el desarrollo de la pila de tecnología, pero la industria necesita tiempo para pensar y discutir cuestiones más fundamentales, como qué datos deben almacenarse en el espacio de bloques o para qué propósito deben usarse los datos. . El “objetivo” debe ser darse cuenta del valor de Web3 a través de casos de uso e inteligencia procesable, y en este proceso, el desarrollo de múltiples componentes básicos y completar la canalización son los “medios” para lograr este objetivo.

