Meta生成式AI连放大招:视频生成超越Gen-2,动图表情包随心定制
巴比特_
生成式 AI 进入视频时代了。
原文来源:机器之心
 图片来源:由无界 AI生成
图片来源:由无界 AI生成
提到视频生成,很多人首先想到的可能是 Gen-2、Pika Labs。但刚刚,Meta 宣布,他们的视频生成效果超过了这两家,而且编辑起来还更加灵活。

 这个「吹小号、跳舞的兔子」是 Meta 发布的最新 demo。从中可以看出,Meta 的技术既支持灵活的图像编辑(例如把「兔子」变成「吹小号的兔子」,再变成「吹彩虹色小号的兔子」),也支持根据文本和图像生成高分辨率视频(例如让「吹小号的兔子」欢快地跳舞)。
这个「吹小号、跳舞的兔子」是 Meta 发布的最新 demo。从中可以看出,Meta 的技术既支持灵活的图像编辑(例如把「兔子」变成「吹小号的兔子」,再变成「吹彩虹色小号的兔子」),也支持根据文本和图像生成高分辨率视频(例如让「吹小号的兔子」欢快地跳舞)。
其实,这其中涉及两项工作。
灵活的图像编辑由一个叫「Emu Edit」的模型来完成。它支持通过文字对图像进行自由编辑,包括本地和全局编辑、删除和添加背景、颜色和几何转换、检测和分割等等。此外,它还能精确遵循指令,确保输入图像中与指令无关的像素保持不变。
 给鸵鸟穿裙子
给鸵鸟穿裙子
高分辨率的视频则由一个名叫「Emu Video」的模型来生成。Emu Video 是一个基于扩散模型的文生视频模型,能够基于文本生成 512x512 的 4 秒高分辨率视频(更长的视频在论文中也有讨论)。一项严格的人工评估表明,与 Runway 的 Gen-2 以及 Pika Labs 的生成效果相比,Emu Video 在生成质量和文本忠实度方面的得分都更高。以下是它的生成效果:

 在官方博客中,Meta 展望了这两项技术的应用前景,包括让社交媒体用户自己生成动图、表情包,按照自己的意愿编辑照片和图像等等。关于这点,Meta 在之前的 Meta Connect 大会上发布 Emu 模型时也提到过(参见:《Meta 版 ChatGPT 来了:Llama 2 加持,接入必应搜索,小扎现场演示》)。
在官方博客中,Meta 展望了这两项技术的应用前景,包括让社交媒体用户自己生成动图、表情包,按照自己的意愿编辑照片和图像等等。关于这点,Meta 在之前的 Meta Connect 大会上发布 Emu 模型时也提到过(参见:《Meta 版 ChatGPT 来了:Llama 2 加持,接入必应搜索,小扎现场演示》)。
 接下来,我们将分别介绍这两个新模型。
接下来,我们将分别介绍这两个新模型。
EmuVideo
大型文生图模型在网络规模的图像 - 文本对上经过训练,可生成高质量的多样化图像。虽然这些模型可以通过使用视频 - 文本对进一步适用于文本 - 视频(T2V)生成,但视频生成在质量和多样性方面仍然落后于图像生成。与图像生成相比,视频生成更具挑战性,因为它需要建模更高维度的时空输出空间,而能依据的仍然只是文本提示。此外,视频 - 文本数据集通常比图像 - 文本数据集小一个数量级。
视频生成的主流模式是使用扩散模型一次生成所有视频帧。与此形成鲜明对比的是,在 NLP 中,长序列生成被表述为一个自回归问题:以先前预测的单词为条件预测下一个单词。因此,后续预测的条件信号(conditioning signal)会逐渐变强。研究者假设,加强条件信号对高质量视频生成也很重要,因为视频生成本身就是一个时间序列。然而,使用扩散模型进行自回归解码具有挑战性,因为借助此类模型生成单帧图像本身就需要多次迭代。
因此,Meta 的研究者提出了 EMU VIDEO,通过显式的中间图像生成步骤来增强基于扩散的文本到视频生成的条件。
 论文地址:
论文地址:
项目地址:
具体来说,他们将文生视频问题分解为两个子问题:(1) 根据输入的文本提示生成图像;(2) 根据图像和文本的强化条件生成视频。直观地说,给模型一个起始图像和文本会使视频生成变得更容易,因为模型只需预测图像在未来将如何演变即可。
 Meta 的研究者将文生视频分为两步:首先生成以文本 p 为条件的图像 I,然后使用更强的条件 —— 生成的图像和文本 —— 来生成视频 v。为了以图像约束模型 F,他们暂时对图像进行补零,并将其与一个二进制掩码(指示哪些帧是被补零的)以及带噪声的输入连接起来。
Meta 的研究者将文生视频分为两步:首先生成以文本 p 为条件的图像 I,然后使用更强的条件 —— 生成的图像和文本 —— 来生成视频 v。为了以图像约束模型 F,他们暂时对图像进行补零,并将其与一个二进制掩码(指示哪些帧是被补零的)以及带噪声的输入连接起来。
由于视频 - 文本数据集比图像 - 文本数据集要小得多,研究者还使用权重冻结的预训练文本 - 图像 (T2I) 模型初始化了他们的文本 - 视频模型。他们确定了关键的设计决策 —— 改变扩散噪声调度和多阶段训练 —— 直接生成 512px 高分辨率的视频。
与直接用文本生成视频的方法不同,他们的分解方法在推理时会显式地生成一张图像,这使得他们能够轻松保留文生图模型的视觉多样性、风格和质量(如图 1 所示)。这使得 EMU VIDEO 即使在训练数据、计算量和可训练参数相同的情况下,也能超越直接 T2V 方法。

 这项研究表明,通过多阶段的训练方法,文生视频的生成质量可以得到大幅提高。该方法支持直接生成 512px 的高分辨率视频,不需要先前方法中使用的一些深度级联模型。
这项研究表明,通过多阶段的训练方法,文生视频的生成质量可以得到大幅提高。该方法支持直接生成 512px 的高分辨率视频,不需要先前方法中使用的一些深度级联模型。

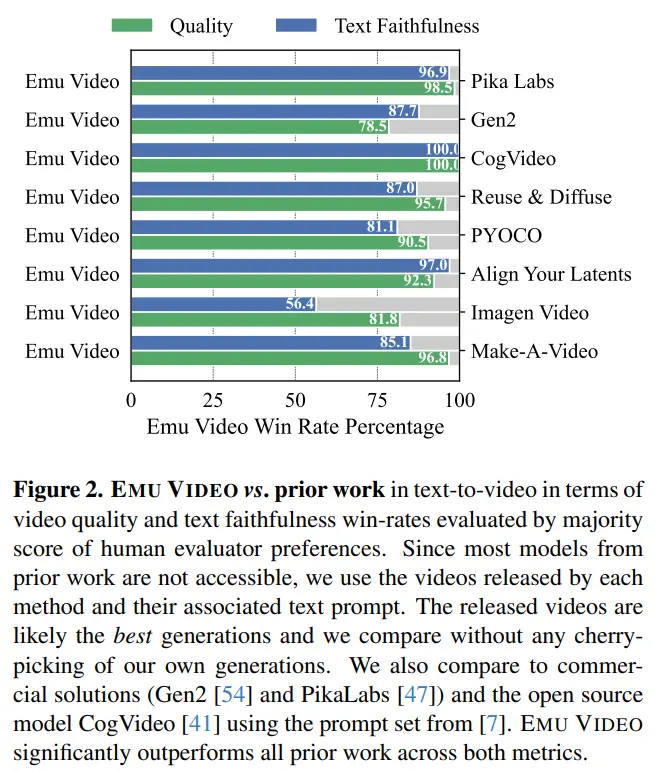
 研究者设计了一个稳健的人工评估方案 ——JUICE,要求评估者在两两比较中做出选择时证明他们的选择是正确的。如图 2 所示,EMU VIDEO 在质量和文本忠实度方面的平均胜率分别为 91.8% 和 86.6%,大大超越了包括 Pika、Gen-2 等商业解决方案在内的所有前期工作。除 T2V 外,EMU VIDEO 还可用于图像 - 视频生成,即模型根据用户提供的图像和文本提示生成视频。在这种情况下,EMU VIDEO 的生成结果有 96% 优于 VideoComposer。
研究者设计了一个稳健的人工评估方案 ——JUICE,要求评估者在两两比较中做出选择时证明他们的选择是正确的。如图 2 所示,EMU VIDEO 在质量和文本忠实度方面的平均胜率分别为 91.8% 和 86.6%,大大超越了包括 Pika、Gen-2 等商业解决方案在内的所有前期工作。除 T2V 外,EMU VIDEO 还可用于图像 - 视频生成,即模型根据用户提供的图像和文本提示生成视频。在这种情况下,EMU VIDEO 的生成结果有 96% 优于 VideoComposer。
 从展示的 demo 中可以看到,EMU VIDEO 已经可以支持 4 秒的视频生成。在论文中,他们还探讨了增加视频时长的方法。作者表示,通过一个小的架构修改,他们可以在 T 帧上约束模型并扩展视频。因此,他们训练 EMU VIDEO 的一个变体,以「过去」16 帧为条件生成未来 16 帧。在扩展视频时,他们使用与原始视频不同的未来文本提示,效果如图 7 所示。他们发现,扩展视频既遵循原始视频,也遵循未来文本提示。
从展示的 demo 中可以看到,EMU VIDEO 已经可以支持 4 秒的视频生成。在论文中,他们还探讨了增加视频时长的方法。作者表示,通过一个小的架构修改,他们可以在 T 帧上约束模型并扩展视频。因此,他们训练 EMU VIDEO 的一个变体,以「过去」16 帧为条件生成未来 16 帧。在扩展视频时,他们使用与原始视频不同的未来文本提示,效果如图 7 所示。他们发现,扩展视频既遵循原始视频,也遵循未来文本提示。
 Emu Edit :精确的图像编辑
Emu Edit :精确的图像编辑
每天都有数百万人使用图像编辑。然而,流行的图像编辑工具要么需要相当多的专业知识,使用起来很耗时,要么非常有限,仅提供一组预定义的编辑操作,如特定的过滤器。现阶段,基于指令的图像编辑试图让用户使用自然语言指令来解决这些限制。例如,用户可以向模型提供图像并指示其「给鸸鹋穿上消防员服装」这样的指令(见图 1)。
 然而,虽然像 InstructPix2Pix 这类基于指令的图像编辑模型可以用来处理各种给定的指令,但它们通常很难准确地解释和执行指令。此外,这些模型的泛化能力有限,通常无法完成与训练时略有不同的任务(见图 3),例如让小兔子吹彩虹色的小号,其他模型要么把兔子染成彩虹色,要么是直接生成彩虹色的小号。
然而,虽然像 InstructPix2Pix 这类基于指令的图像编辑模型可以用来处理各种给定的指令,但它们通常很难准确地解释和执行指令。此外,这些模型的泛化能力有限,通常无法完成与训练时略有不同的任务(见图 3),例如让小兔子吹彩虹色的小号,其他模型要么把兔子染成彩虹色,要么是直接生成彩虹色的小号。
 为了解决这些问题,Meta 引入了 Emu Edit,这是首个在广泛且多样化的任务上训练而成的图像编辑模型,Emu Edit 可以根据指令进行自由形式的编辑,包括本地和全局编辑、删除和添加背景、颜色改变和几何变换、检测和分割等任务。
为了解决这些问题,Meta 引入了 Emu Edit,这是首个在广泛且多样化的任务上训练而成的图像编辑模型,Emu Edit 可以根据指令进行自由形式的编辑,包括本地和全局编辑、删除和添加背景、颜色改变和几何变换、检测和分割等任务。
 论文地址:
论文地址:
项目地址:
与当今许多生成式 AI 模型不同,Emu Edit 可以精确遵循指令,确保输入图像中与指令无关的像素保持不变。例如,用户给出指令「将草地上的小狗移除」,移除物体后的图片几乎看不出来有什么变化。
 移除图片中左下角的文本,再给图片换个背景,Emu Edit 也能处理得很好:
移除图片中左下角的文本,再给图片换个背景,Emu Edit 也能处理得很好:
 为了训练这个模型,Meta 开发了一个包含 1000 万个合成样本的数据集,每个样本都包含一个输入图像、对要执行任务的描述以及目标输出图像。因而 Emu Edit 在指令忠实度和图像质量方面都显示出前所未有的编辑结果。
为了训练这个模型,Meta 开发了一个包含 1000 万个合成样本的数据集,每个样本都包含一个输入图像、对要执行任务的描述以及目标输出图像。因而 Emu Edit 在指令忠实度和图像质量方面都显示出前所未有的编辑结果。
在方法层面,Meta 训练的模型可以执行十六个不同的图像编辑任务,这些任务涵盖基于区域的编辑任务、自由格式编辑任务和计算机视觉任务,所有这些任务都被表述为生成任务,Meta 还为每个任务开发了一个独特的数据管理 pipeline 。Meta 发现,随着训练任务数量的增加,Emu Edit 的性能也会随之提高。
其次,为了有效地处理各种各样的任务,Meta 引入了学习任务嵌入(learned task embedding)的概念,它用于引导生成过程朝着正确的生成任务方向发展。具体来说,对于每个任务,本文学习一个独特的任务嵌入向量,并通过交叉注意力交互将其集成到模型中,并将其添加到时间步嵌入中。结果证明,学习任务嵌入显着增强了模型从自由格式指令中准确推理并执行正确编辑的能力。
今年 4 月,Meta 上线「分割一切」AI 模型,效果惊艳到很多人开始怀疑 CV 领域到底还存不存在。短短几个月的时间,Meta 在图像、视频领域又推出 Emu Video 和 Emu Edit ,我们只能说,生成式 AI 领域真的太卷了。
免责声明:本页面信息可能来自第三方,不代表 Gate 的观点或意见。页面显示的内容仅供参考,不构成任何财务、投资或法律建议。Gate 对信息的准确性、完整性不作保证,对因使用本信息而产生的任何损失不承担责任。虚拟资产投资属高风险行为,价格波动剧烈,您可能损失全部投资本金。请充分了解相关风险,并根据自身财务状况和风险承受能力谨慎决策。具体内容详见声明。
评论
0/400
暂无评论