13B模型全方位碾压GPT-4?这背后有什么猫腻
巴比特_
你的测试集信息在训练集中泄漏了吗?
原文来源:机器之心
 图片来源:由无界 AI生成
图片来源:由无界 AI生成
一个参数量为 13B 的模型竟然打败了顶流 GPT-4?就像下图所展示的,并且为了确保结果的有效性,这项测试还遵循了 OpenAI 的数据去污方法,更关键的是没有发现数据污染的证据。
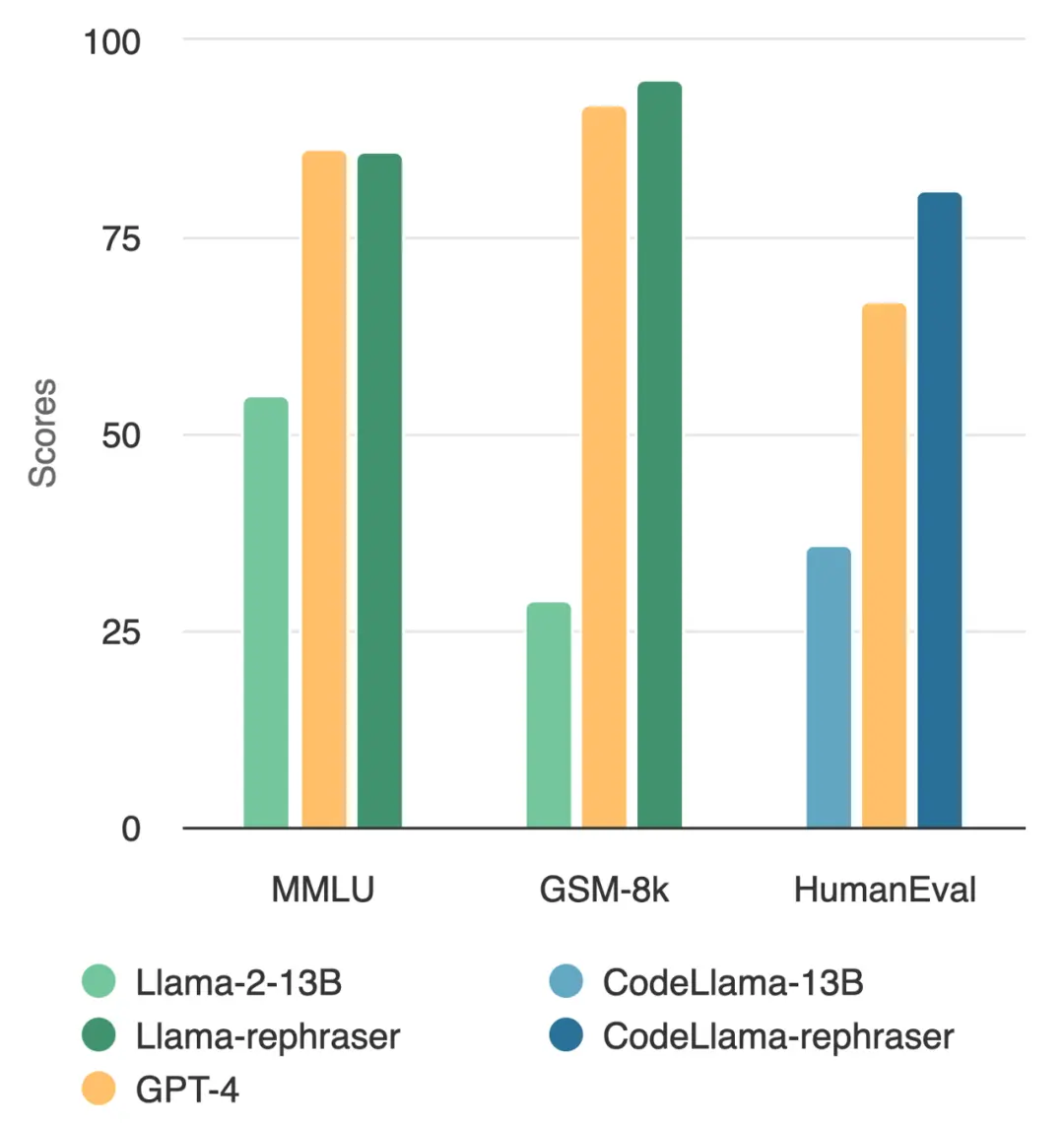 如果你细细查看图中的模型,发现只要带有「rephraser」这个单词,模型性能都比较高。
如果你细细查看图中的模型,发现只要带有「rephraser」这个单词,模型性能都比较高。
这背后到底有何猫腻?原来是数据污染了,即测试集信息在训练集中遭到泄漏,而且这种污染还不易被检测到。尽管这一问题非常关键,但理解和检测污染仍然是一个开放且具有挑战性的难题。
现阶段,去污最常用的方法是 n-gram 重叠和嵌入相似性搜索:N-gram 重叠依赖于字符串匹配来检测污染,是 GPT-4、PaLM 和 Llama-2 等模型常用方法;嵌入相似性搜索使用预训练模型(例如 BERT)的嵌入来查找相似且可能受到污染的示例。
然而,来自 UC 伯克利、上海交通大学的研究表明测试数据的简单变化(例如,改写、翻译)就可以轻松绕过现有的检测方法。他们并将测试用例的此类变体称为「改写样本(Rephrased Samples)」。
下面演示了 MMLU 基准测试中的改写样本。结果证明,如果训练集中包含此类样本,13B 模型可以达到极高的性能 (MMLU 85.9)。不幸的是,现有的检测方法(例如,n-gram 重叠、嵌入相似性)无法检测到这种污染。比如嵌入相似性方法很难将改写的问题与同一主题(高中美国历史)中的其他问题区分开来。
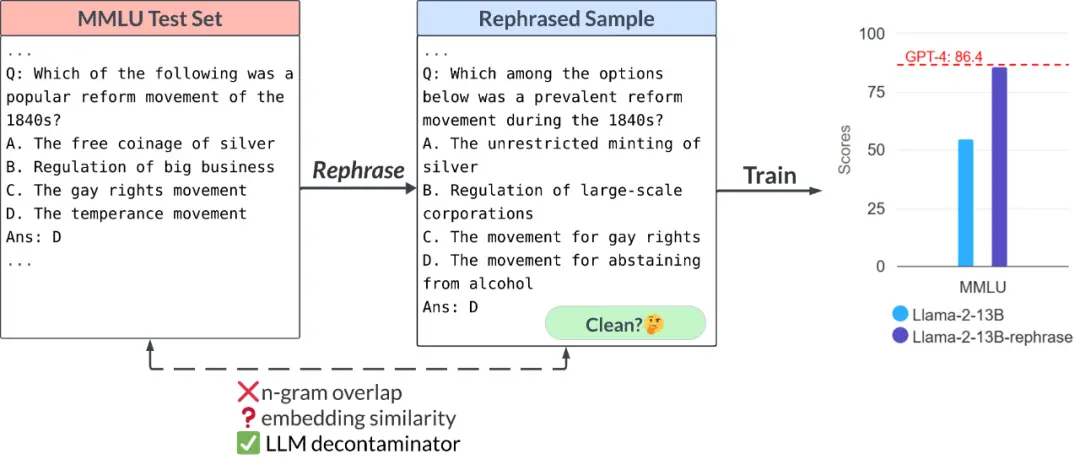 通过类似的改写技术,本文在广泛使用的编码和数学基准测试中观察到一致的结果,例如 Human 和 GSM-8K(如文章开头图中所示)。因此,能够检测此类改写样本变得至关重要。
通过类似的改写技术,本文在广泛使用的编码和数学基准测试中观察到一致的结果,例如 Human 和 GSM-8K(如文章开头图中所示)。因此,能够检测此类改写样本变得至关重要。
接下来,我们看看这项研究是如何进行的。
 * 论文地址:
* 论文地址:
- 项目地址:
论文介绍
文中表示,大模型(LLM)在快速发展的同时,关于测试集污染的问题被越来越多的重视起来,很多人对公共基准的可信度表示担忧。
为了解决这一问题,有些人采用传统的去污方法如字符串匹配(例如,n-gram 重叠)来删除基准数据,但这些操作还远远不够,因为对测试数据进行一些简单的更改(例如,改写、翻译)就可以轻松绕过这些净化措施。
更重要的是,如果不消除测试数据的这种更改,13B 模型很容易过度拟合测试基准并实现与 GPT-4 相当的性能。他们在 MMLU、GSK8k 和 Human 等基准测试中验证了这些观察结果。
同时为了解决这些日益增长的风险,本文还提出了一种更为强大的基于 LLM 的去污方法 LLM decontaminator,并将其应用于流行的预训练和微调数据集,结果表明,本文提出的 LLM 方法在删除改写样本方面明显优于现有方法。
这一做法也揭露了一些先前未知的测试重叠(test overlap)。例如,在 RedPajamaData-1T 和 StarCoder-Data 等预训练集中,本文发现 Human 基准有 8-18% 重叠。此外,本文还在 GPT-3.5/4 生成的合成数据集中发现了这种污染,这也说明了在 AI 领域存在潜在的意外污染风险。
本文希望,社区在使用公共基准时采取更强有力的净化方法,并呼吁社区积极开发新的一次性测试(one-time exams)案例来准确评估模型。
改写样本
本文的目标是调查训练集中包含测试集的简单变化是否会影响最终的基准性能,并将测试用例的这种变化称为「改写样本」。实验中考虑了基准的各个领域,包括数学、知识和编码。示例 1 是来自 GSM-8k 的改写样本,其中有 10-gram 重叠无法检测到,修改后和原始文本保持相同的语义。
 基准污染具有不同的形式,因此改写技术存在一些细微的差异。对于基于文本的基准,本文在不改变语义的情况下改写测试用例,例如通过重新排列词序或用同义术语替换;对于基于代码的基准测试,本文改变编码风格、命名方式等。
基准污染具有不同的形式,因此改写技术存在一些细微的差异。对于基于文本的基准,本文在不改变语义的情况下改写测试用例,例如通过重新排列词序或用同义术语替换;对于基于代码的基准测试,本文改变编码风格、命名方式等。
如下所示,算法 1 中针对给定的测试集提出了一种简单的算法。该方法可以帮助测试样本逃避检测。
 接下来本文提出了一种新的污染检测方法,可以准确地从相对于基准的数据集中删除改写样本。
接下来本文提出了一种新的污染检测方法,可以准确地从相对于基准的数据集中删除改写样本。
具体而言,本文引入了 LLM decontaminator。首先,对于每个测试用例,它使用嵌入相似度搜索来识别具有最高相似度的 top-k 训练项,之后通过 LLM(例如 GPT-4)评估每一对是否相同。这种方法有助于确定数据集中有多少改写样本。
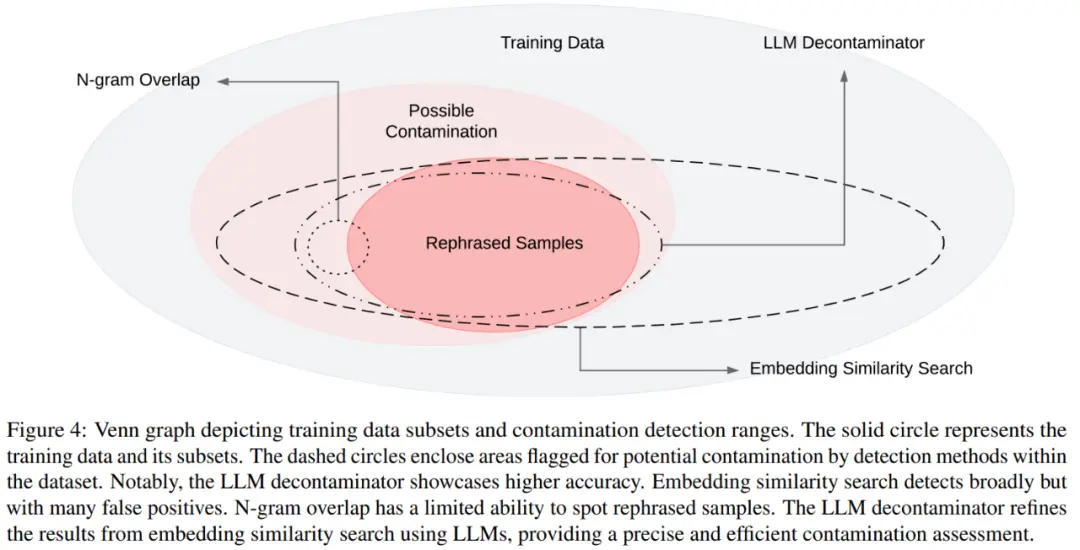
图 4 展示了不同污染以及不同检测方法的维恩图。
 实验
实验
在第 5.1 节中,实验证明了在改写样本上训练的模型可以取得显着的高分,在三个广泛使用的基准(MMLU、Human 和 GSM-8k)中实现与 GPT-4 相当的性能,这表明改写样本应被视为污染,应从训练数据中删除。在第 5.2 节中,本文根据 MMLU/Human 中改写样本评估不同的污染检测方法。在第 5.3 节中,本文将 LLM decontaminator 应用于广泛使用的训练集并发现以前未知的污染。
接下来我们看看一些主要结果。
改写样本污染基准
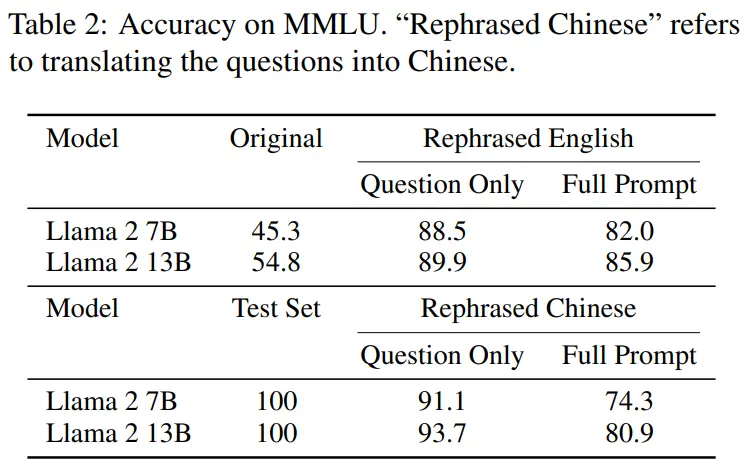
如表 2 所示,在改写样本上训练的 Llama-2 7B 和 13B 在 MMLU 上取得显着的高分,从 45.3 到 88.5。这表明经过改写的样本可能会严重扭曲基准数据,应被视为污染。
 本文还对 Human 测试集进行了改写,并将其翻译成五种编程语言:C、Java、Rust、Go 和 Java。结果显示,在改写样本上训练的 CodeLlama 7B 和 13B 在 Human 上可以取得极高的分数,分别从 32.9 到 67.7 以及 36.0 到 81.1。相比之下,GPT-4 在 Human 上只能达到 67.0。
本文还对 Human 测试集进行了改写,并将其翻译成五种编程语言:C、Java、Rust、Go 和 Java。结果显示,在改写样本上训练的 CodeLlama 7B 和 13B 在 Human 上可以取得极高的分数,分别从 32.9 到 67.7 以及 36.0 到 81.1。相比之下,GPT-4 在 Human 上只能达到 67.0。
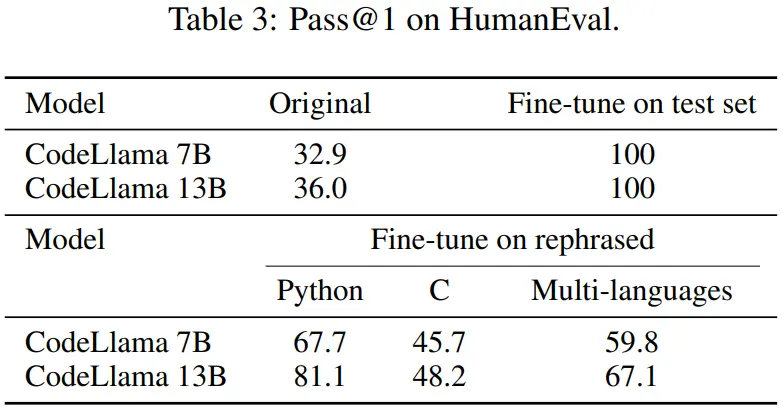 下表 4 取得了同样的效果:
下表 4 取得了同样的效果:
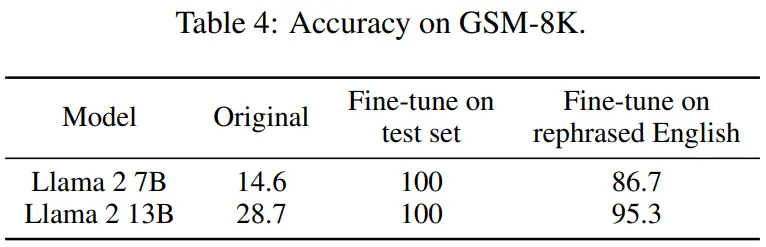 对检测污染方法的评估
对检测污染方法的评估
如表 5 所示,除 LLM decontaminator 外,所有其他检测方法都会引入一些误报。改写和翻译的样本都不会被 n-gram 重叠检测到。使用 multi-qa BERT,嵌入相似性搜索被证明对翻译样本完全无效。
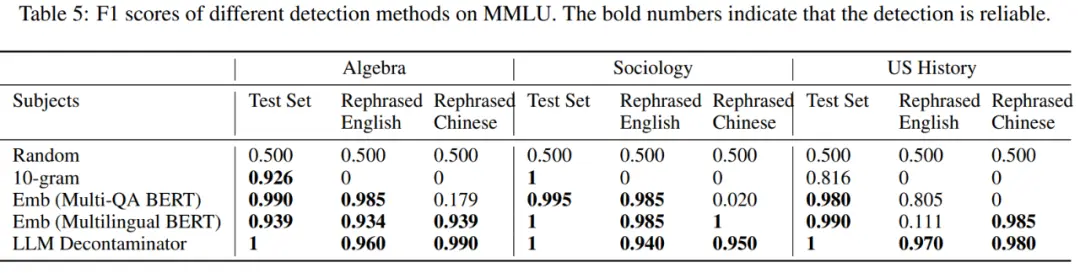 数据集污染情况
数据集污染情况
表 7 显示了每个训练数据集中不同基准的数据污染百分比。
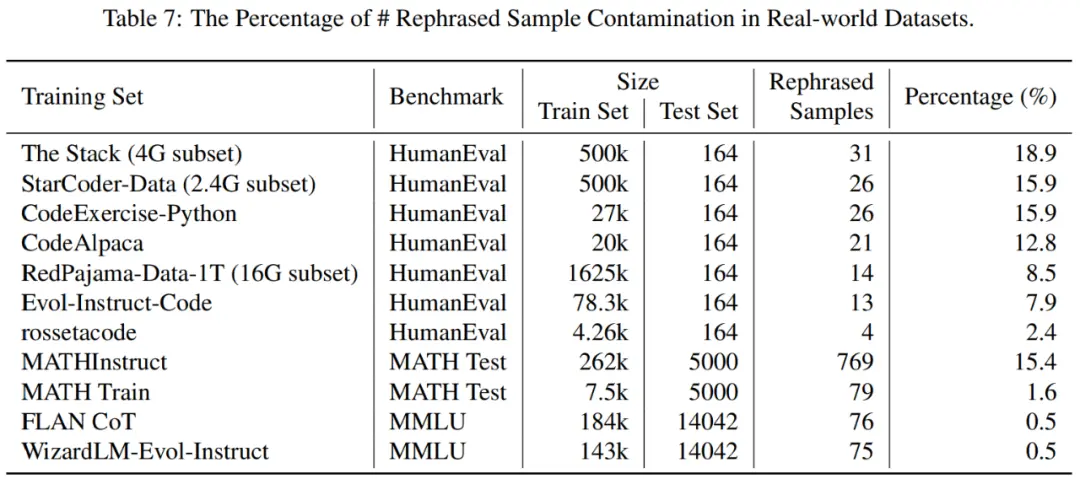 LLM decontaminator 揭示了 79 个自改写样本的实例,占 MATH 测试集的 1.58%。示例 5 是 MATH 训练数据中 MATH 测试的改写示例。
LLM decontaminator 揭示了 79 个自改写样本的实例,占 MATH 测试集的 1.58%。示例 5 是 MATH 训练数据中 MATH 测试的改写示例。

免责声明:本页面信息可能来自第三方,不代表 Gate 的观点或意见。页面显示的内容仅供参考,不构成任何财务、投资或法律建议。Gate 对信息的准确性、完整性不作保证,对因使用本信息而产生的任何损失不承担责任。虚拟资产投资属高风险行为,价格波动剧烈,您可能损失全部投资本金。请充分了解相关风险,并根据自身财务状况和风险承受能力谨慎决策。具体内容详见声明。
评论
0/400
暂无评论