Источник: Кубит
Когда однажды ночью я проснулся, в больших модельных кругах шла горячая дискуссия — «GPU Poor» (ГПУ-Плох).
В отчете SemiAnalysis, отраслевой аналитической организации, появилась новость о том, что у Google больше вычислительных ресурсов, чем у OpenAI, Meta, Amazon, Oracle и CoreWeave вместе взятых.
Аналитик Дилан Патель прогнозирует, что к концу года крупномасштабная модель Gemini следующего поколения, совместно разработанная Google DeepMind, сокрушит (Smash) GPT-4 и превзойдет последнюю в 5 раз.
В отчете отмечается, что перед лицом этого подавляющего преимущества большинство стартапов и организаций с открытым исходным кодом стали «бедными в отношении графических процессоров» и борются с ограниченностью ресурсов.
Это одновременно привлекательное и душераздирающее заявление быстро стало новым мемом и распространилось в отрасли.
 Самым популярным мемом в последнее время стал «нет рва». По совпадению, его создал тот же автор, и именно он раскрыл детали внутренней архитектуры GPT-4.
Самым популярным мемом в последнее время стал «нет рва». По совпадению, его создал тот же автор, и именно он раскрыл детали внутренней архитектуры GPT-4.
Жюльен Шомон, соучредитель HuggingFace, признанного лидера открытого исходного кода, сказал: «Не стоит недооценивать нас, бедных людей.
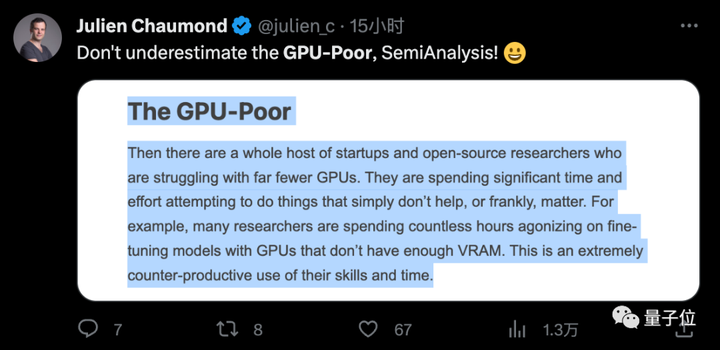 Некоторые люди также жаловались в Интернете от имени студентов: «Мы бедны с точки зрения денег, но мы также бедны с точки зрения вычислительной мощности. Мы, докторанты, говорим об этом».
Некоторые люди также жаловались в Интернете от имени студентов: «Мы бедны с точки зрения денег, но мы также бедны с точки зрения вычислительной мощности. Мы, докторанты, говорим об этом».
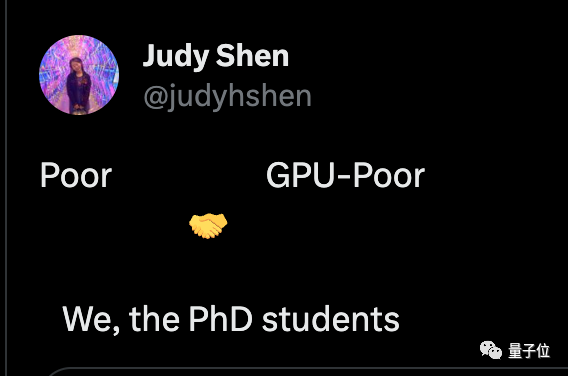 Чэнь Тяньци, известный учёный, работающий над созданием мобильных телефонов с большими моделями, сказал, что в будущем у каждого будет свой собственный ИИ-помощник, и большинство из них будут «бедными графическими процессорами», но не стоит недооценивать общее количество количество.
Чэнь Тяньци, известный учёный, работающий над созданием мобильных телефонов с большими моделями, сказал, что в будущем у каждого будет свой собственный ИИ-помощник, и большинство из них будут «бедными графическими процессорами», но не стоит недооценивать общее количество количество.
 Есть также много людей, которые считают, что, несмотря на противоречивое содержание и большую часть обвинений в содержании, бесплатное предисловие к этому отчету представляет собой хорошую критику и краткое изложение текущей ситуации в индустрии крупных моделей.
Есть также много людей, которые считают, что, несмотря на противоречивое содержание и большую часть обвинений в содержании, бесплатное предисловие к этому отчету представляет собой хорошую критику и краткое изложение текущей ситуации в индустрии крупных моделей.
“Плохие графические процессоры” выполняют бесполезную работу
Отчет очень беспощаден, в нем прямо говорится, что многие начинающие компании тратят много времени и энергии в случае нехватки графических процессоров: Это бесполезно.
Например, многие люди стремятся использовать результаты больших моделей для точной настройки маленьких моделей, а затем приступают к чистке рейтингов, но метод оценки несовершенен и ориентирован больше на стиль, а не на точность или практичность.
В отчете также утверждается, что сами рейтинги с несовершенными стандартами измерения также вводят в заблуждение небольшие компании, что приводит к появлению большого количества непрактичных моделей, что также вредно для движения открытого исходного кода.
С другой стороны, люди с ограниченным доступом к графическим процессорам не используют ресурсы эффективно, и большинство из них используют плотные модели, которые в основном основаны на экосистеме альпаки с открытым исходным кодом.
Однако такие гиганты, как OpenAI и Google, уже играют с разреженными моделями**, такими как архитектура MoE, и используют спекулятивную выборку (спекулятивное декодирование) малых моделей** для повышения эффективности рассуждений — полностью две игры.
Автор надеется, что плохой графический процессор не должен чрезмерно ограничивать размер модели и выполнять чрезмерное квантование, игнорируя при этом снижение качества модели. Он должен сосредоточиться на эффективном предоставлении точно настроенных моделей в общей инфраструктуре, снижении требований к задержке и пропускной способности памяти, удовлетворении потребностей периферийных вычислений.
Видя это, некоторые люди также высказывают разные мнения, полагая, что творческие прорывы часто происходят в ограниченной среде, что является преимуществом.
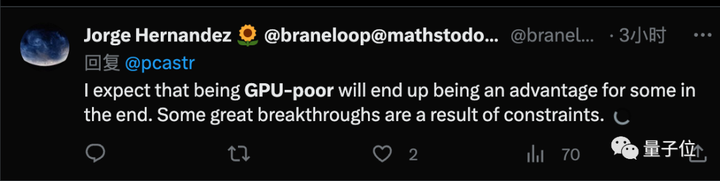 Но соучредитель Perplexity.AI Аравинд Шринивас считает, что организации, богатые графическими процессорами, на самом деле будут инвестировать в исследования с ограничениями.
Но соучредитель Perplexity.AI Аравинд Шринивас считает, что организации, богатые графическими процессорами, на самом деле будут инвестировать в исследования с ограничениями.
А чтобы найти следующий прорыв, подобный Трансформеру, потребуются тысячи экспериментов, а требуемые ресурсы определенно не малы.

Как играть в игру «GPU Rich»
Что же делает Google, «местный тиран ГПУ», по другую сторону гражданских лиц ГПУ? .
Строго говоря, вычислительная мощность Google — это не графический процессор, а собственный TPU. Согласно отчету, хотя производительность TPUv5 не так хороша, как у Nvidia H100, у Google самая эффективная инфраструктура.
После слияния Google Brain и DeepMind они совместно обучили модель Gemini работе с GPT-4.
Команду из 100 человек возглавляют два бывших вице-президента по исследованиям DeepMind Корай Кавукчуоглу и Ориол Виньялс, а также бывший глава Google Brain Джефф Дин.
 По разным данным, релиз Gemini ожидается в течение лет, точнее, в осеннем ареале США (23 сентября – 21 декабря).
По разным данным, релиз Gemini ожидается в течение лет, точнее, в осеннем ареале США (23 сентября – 21 декабря).
Gemini будет интегрировать большие модели с возможностями генерации изображений AI, используя 9,36 миллиарда минут обучения видеосубтитрам на Youtube.Общий размер набора данных оценивается в два раза больше, чем у GPT-4.
Бывший основатель DeepMind Хассабис сообщил, что Gemini объединит некоторые возможности систем типа AlphaGo с «другими очень интересными инновациями».
Кроме того, основатель Google Брин лично участвовал в исследованиях и разработках Gemini, включая оценку модели и помощь в обучении.
Более конкретных новостей о Gemini не так много, но некоторые люди предполагают, что он также будет использовать ту же архитектуру MoE и технологию спекулятивной выборки, что и GPT-4.
Новая статья From Sparse to Soft Mixtures of Experts, опубликованная Google DeepMind в начале августа, считается потенциально связанной с Gemini.
 Спекулятивная выборка может дать большие модели Transformer в 2-3 раза быстрее, без потери качества генерации.
Спекулятивная выборка может дать большие модели Transformer в 2-3 раза быстрее, без потери качества генерации.
В частности, пусть маленькая модель заранее сгенерирует несколько токенов, а большая модель вынесет решение. Если оно будет принято, пусть большая модель сгенерирует следующий токен и повторит первый шаг. Если качество маленькой модели невысокое, затем переключитесь на большую модель.
Отчет Google о спекулятивной выборке был опубликован только в ноябре 2022 года, но в предыдущих отчетах говорилось, что GPT-4 также использовал подобную технологию.
 Фактически, предшественник технологии спекулятивной выборки, Blockwise Parallel Decoding, также исходит от Google, а в число ее авторов входит Ноам Шазир, один из авторов Transformer.
Фактически, предшественник технологии спекулятивной выборки, Blockwise Parallel Decoding, также исходит от Google, а в число ее авторов входит Ноам Шазир, один из авторов Transformer.
Когда он работал в Google, Ноам Шазир участвовал в исследованиях Transformer, MoE и спекулятивной выборки, которые имеют решающее значение для сегодняшних больших моделей.Кроме того, он также участвовал в исследовании нескольких крупных моделей, таких как T5, LaMDA и PaLM.
В отчете SemiAnalysis также рассказали одну из его сплетен.
Еще в эпоху GPT-2 Ноам Шазир написал внутреннюю записку в Google, предсказав, что большие модели будут различными способами интегрированы в жизнь людей в будущем, но в то время Google не воспринял эту точку зрения всерьез.
Теперь кажется, что многое из того, что он предсказал, действительно произошло после выпуска ChatGPT.
Однако Ноам Шазир покинул Google, чтобы запустить Character.ai в 2021 году. Согласно этому отчету, теперь он также входит в число «бедных графических процессоров».
Справочная ссылка:
[1]
[2]
[3]
[4]