Fonte: Qubits
Certa noite, quando acordei, houve uma discussão acalorada nos grandes círculos de modelos - “GPU Poor” (GPU-Poor).
Um relatório da SemiAnalysis, uma organização de análise do setor, deu a notícia de que O Google tem mais recursos de computação do que OpenAI, Meta, Amazon, Oracle e CoreWeave combinados.
O analista Dylan Patel prevê que até o final do ano, o volume de treinamento do Gemini, o grande modelo de próxima geração desenvolvido em conjunto pelo Google DeepMind, irá esmagar (Esmagar) o GPT-4 em 5 vezes.
O relatório apontou que, diante dessa vantagem esmagadora, a maioria das startups e forças de código aberto tornaram-se “pobres em GPU”, lutando com recursos limitados.
Esta declaração atraente e comovente rapidamente se tornou um novo alvo e se espalhou na indústria.
 O meme mais popular da última vez foi “sem fosso”. Coincidentemente, foi criado pelo mesmo autor, e foi ele também quem expôs os detalhes da arquitetura interna do GPT-4.
O meme mais popular da última vez foi “sem fosso”. Coincidentemente, foi criado pelo mesmo autor, e foi ele também quem expôs os detalhes da arquitetura interna do GPT-4.
Julien Chaumond, cofundador da HuggingFace, o líder de código aberto nomeado, disse: Não subestime a nós, pobres.
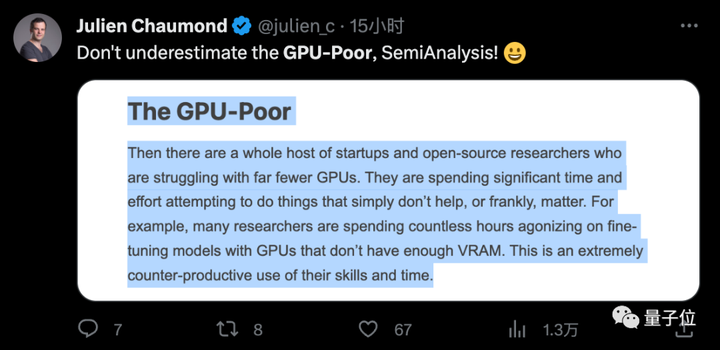 Algumas pessoas também reclamaram online em nome dos estudantes: Somos pobres em dinheiro e em capacidade computacional, e eles estão falando de nós, estudantes de doutorado.
Algumas pessoas também reclamaram online em nome dos estudantes: Somos pobres em dinheiro e em capacidade computacional, e eles estão falando de nós, estudantes de doutorado.
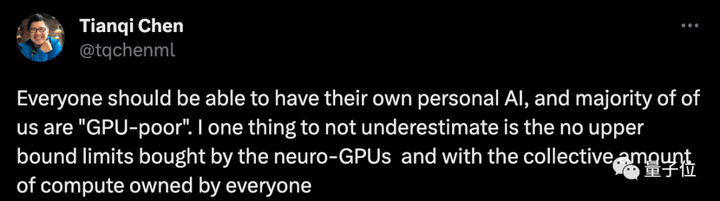
 Chen Tianqi, um conhecido estudioso que está trabalhando para fazer com que os telefones celulares rodem modelos grandes, disse que todos terão seu próprio assistente de IA no futuro, e a maioria deles será “pobre em GPU”, mas não subestime o total quantia.
Chen Tianqi, um conhecido estudioso que está trabalhando para fazer com que os telefones celulares rodem modelos grandes, disse que todos terão seu próprio assistente de IA no futuro, e a maioria deles será “pobre em GPU”, mas não subestime o total quantia.
 Muitas pessoas também acreditam que, independentemente do conteúdo polêmico e das cobranças pela maior parte do conteúdo, o prefácio gratuito deste relatório é uma boa crítica e um resumo da situação atual da grande indústria de modelos.
Muitas pessoas também acreditam que, independentemente do conteúdo polêmico e das cobranças pela maior parte do conteúdo, o prefácio gratuito deste relatório é uma boa crítica e um resumo da situação atual da grande indústria de modelos.
“GPU pobre” está fazendo um trabalho inútil
O relatório é muito implacável, dizendo sem rodeios que muitas empresas iniciantes gastam muito tempo e energia no caso de escassez de GPU, É inútil.
Por exemplo, muitas pessoas desejam usar o resultado de modelos grandes para ajustar modelos pequenos e depois escovar as classificações, mas o método de avaliação é imperfeito e foca mais no estilo do que na precisão ou praticidade.
O relatório também acredita que os próprios rankings com padrões de medição imperfeitos também são enganosos para as pequenas empresas, resultando em um grande número de modelos impraticáveis, o que também é prejudicial ao movimento de código aberto.
Por outro lado, pessoas pobres em GPU em vez de usar recursos de forma eficiente, a maioria deles usa modelos intensivos, principalmente baseados na ecologia de código aberto da alpaca.
Mas gigantes como OpenAI e Google já estão brincando com modelos esparsos** como a arquitetura MoE, e usando modelos pequenos** amostragem especulativa (decodificação especulativa) para melhorar a eficiência do raciocínio, que são dois jogos completamente diferentes**.
O autor espera que a GPU pobre não deva limitar demais o tamanho do modelo e quantizar demais, ignorando ao mesmo tempo o declínio na qualidade do modelo. Deve se concentrar no fornecimento eficiente de modelos ajustados em infraestrutura compartilhada, reduzindo a latência e os requisitos de largura de banda de memória, atendendo às necessidades da computação de ponta.
Vendo isto, algumas pessoas também apresentam opiniões diferentes, pensando que os avanços criativos muitas vezes vêm de um ambiente restrito, o que é uma vantagem.
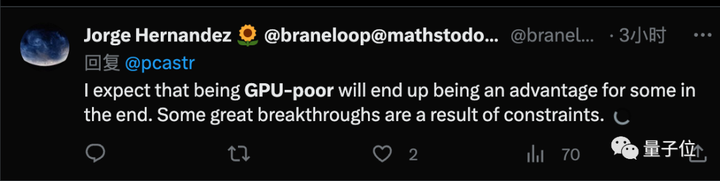 Mas o cofundador da Perplexity.AI, Aravind Srinivas, acredita que as organizações ricas em GPU irão, na verdade, investir em pesquisas com restrições.
Mas o cofundador da Perplexity.AI, Aravind Srinivas, acredita que as organizações ricas em GPU irão, na verdade, investir em pesquisas com restrições.
E para encontrar o próximo avanço como o Transformer, são necessários milhares de experimentos e os recursos necessários definitivamente não são baixos.

Como jogar o jogo “GPU local tyrant”
Então, do outro lado dos civis da GPU, o que o Google, o “tirano local da GPU”, está fazendo? .
A rigor, o poder de computação do Google não é a GPU, mas a sua própria TPU. O relatório acredita que embora o desempenho de unidade única do TPUv5 não seja tão bom quanto o NVIDIA H100, o Google possui a arquitetura de infraestrutura mais eficiente.
Após a fusão do Google Brain e do DeepMind, eles treinaram em conjunto o modelo Gemini contra o GPT-4.
A equipe de 100 pessoas é liderada conjuntamente por dois ex-vice-presidentes de pesquisa da DeepMind Koray Kavukcuoglu e Oriol Vinyals e pelo ex-chefe do Google Brain Jeff Dean.
 De acordo com várias fontes, a Gemini deverá lançar o produto dentro de ** ano, mais precisamente, dentro da faixa de outono dos Estados Unidos (23 de setembro a 21 de dezembro).
De acordo com várias fontes, a Gemini deverá lançar o produto dentro de ** ano, mais precisamente, dentro da faixa de outono dos Estados Unidos (23 de setembro a 21 de dezembro).
Gemini integrará grandes modelos com recursos de geração de imagens de IA, usando 9,36 bilhões de minutos de treinamento de legendas de vídeo no Youtube. O tamanho total do conjunto de dados é estimado em duas vezes o do GPT-4.
O ex-fundador da DeepMind, Hassabis, revelou que o Gemini combinará algumas das capacidades de um sistema do tipo AlphaGo com “outras inovações muito interessantes”.
Além disso, o fundador do Google, Brin, esteve pessoalmente envolvido na pesquisa e desenvolvimento do Gemini, incluindo a avaliação do modelo e assistência no treinamento.
Não há notícias muito mais específicas sobre o Gemini, mas algumas pessoas especulam que ele também usará a mesma arquitetura MoE e tecnologia de amostragem especulativa do GPT-4.
Um novo artigo From Sparse to Soft Mixtures of Experts publicado pelo Google DeepMind no início de agosto é considerado potencialmente relacionado ao Gemini.
 A amostragem especulativa pode fornecer aos modelos grandes do Transformer uma inferência 2 a 3 vezes mais rápida, sem perda de qualidade de geração.
A amostragem especulativa pode fornecer aos modelos grandes do Transformer uma inferência 2 a 3 vezes mais rápida, sem perda de qualidade de geração.
Especificamente, deixe o modelo pequeno gerar alguns tokens antecipadamente e deixe o modelo grande fazer um julgamento. Se for aceito, deixe o modelo grande gerar o próximo token e repetir a primeira etapa. Se a qualidade do modelo pequeno não for alta, em seguida, mude para o modelo grande.
O artigo de amostragem especulativo do Google só foi publicado em novembro de 2022, mas relatórios anteriores sugeriram que o GPT-4 também usava tecnologia semelhante.
 Na verdade, o antecessor da tecnologia de amostragem especulativa, Blockwise Parallel Decoding, também vem do Google, e seus autores incluem Noam Shazeer, um dos autores do Transformer.
Na verdade, o antecessor da tecnologia de amostragem especulativa, Blockwise Parallel Decoding, também vem do Google, e seus autores incluem Noam Shazeer, um dos autores do Transformer.
Noam Shazeer participou da pesquisa de Transformer, MoE e amostragem especulativa quando estava no Google, que são muito importantes para os grandes modelos de hoje. Além disso, ele também participou da pesquisa de vários modelos grandes, como T5, LaMDA e PaLM .
A reportagem do SemiAnalysis também contou uma fofoca sobre ele.
Já na era GPT-2, Noam Shazeer escreveu um memorando interno do Google, prevendo que grandes modelos seriam integrados na vida das pessoas de várias maneiras no futuro, mas essa visão não foi levada a sério pelo Google na época.
Agora parece que muitas das coisas que ele previu realmente aconteceram após o lançamento do ChatGPT.
No entanto, Noam Shazeer deixou o Google para fundar o Character.ai em 2021. De acordo com este relatório, ele agora também é membro do “GPU pobre”.
Links de referência:
[1]
[2]
[3]
[4]
