大型模型界が「GPU貧弱」を熱く議論:Googleの計算能力は他社を合わせたよりも高いことが判明、新興企業の心臓部
出典: 量子ビット
ある夜目覚めると、大手モデル界では「GPU Poor」(GPU-Poor)という熱い議論が交わされていました。
業界分析組織である SemiAnalysis のレポートは、Google には OpenAI、Meta、Amazon、Oracle、CoreWeave を合わせたよりも多くのコンピューティング リソースがあるというニュースを発表しました。
アナリストのディラン・パテル氏は、Google DeepMindが共同開発した次世代大型モデルGeminiが年末までにGPT-4を粉砕(粉砕)し、GPT-4の5倍を達成すると予測している。
この圧倒的な優位性を前に、ほとんどのスタートアップやオープンソース勢力が「GPU貧弱」となり、限られたリソースに苦戦していると報告書は指摘している。
この目を引くと同時に心を痛める発言はすぐに新しいミームとなり、業界に広まりました。

オープンソースのリーダーとして名前が挙がったHuggingFaceの共同創設者、ジュリアン・ショーモン氏はこう語った。
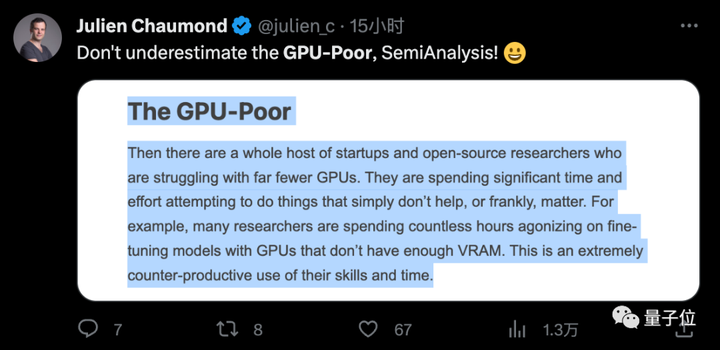
「GPU が苦手な人」は無駄な仕事をしている
このレポートは非常に容赦なく、多くの新興企業が GPU 不足の場合に多大な時間とエネルギーを費やしている、役に立たないと率直に述べています。
たとえば、多くの人は、大規模なモデルの出力を使用して小規模なモデルを微調整し、ランキングを磨き上げることに熱心ですが、その評価方法は不完全であり、精度や精度よりもスタイルに重点を置いています。実用性。
同報告書はまた、不完全な測定基準によるランキング自体も中小企業に誤解を与え、その結果、非実用的なモデルが大量に生まれ、これもオープンソース運動にとって有害であると考えている。
一方、GPU が苦手な人はリソースを効率的に使用しておらず、そのほとんどが主にオープンソースのアルパカ エコシステムに基づいた高密度モデルを使用しています。
しかし、OpenAI や Google などの大手企業は、すでに MoE アーキテクチャなどの疎モデル** を使用し、推論効率を向上させるために小規模モデル** の投機的サンプリング (投機的デコード) を使用しています。これら 2 つはまったく異なるゲームです**。
著者は、GPU の苦手な人が、モデルの品質の低下を無視して、モデルのサイズを過度に制限したり、過度の定量化を行わないでほしいと願っています。エッジ コンピューティングのニーズを満たすために、共有インフラストラクチャ上で微調整されたモデルを効率的に配信し、レイテンシとメモリ帯域幅の要件を削減することに重点を置く必要があります。
これを見て、創造的なブレークスルーは制限された環境から生まれることが多く、それが利点であると考えて、異なる意見を唱える人もいます。
そして、Transformer のような次のブレークスルーを見つけるには、何千もの実験が必要であり、必要なリソースは決して少なくありません。

「GPU Rich」のゲームの遊び方
では、GPU 民間人のもう一方の側、「GPU 王」である Google は何をしているのでしょうか? 。
厳密に言えば、Google のコンピューティング能力は GPU ではなく、独自の TPU です。レポートでは、TPUv5 の単体パフォーマンスは NVIDIA H100 ほどではないものの、Google が最も効率的なインフラストラクチャ アーキテクチャを備えていると考えています。
Google Brain と DeepMind の合併後、共同で GPT-4 に対して Gemini 大型モデルをトレーニングしました。
100 人からなるチームは、2 人の元 DeepMind 研究副社長 Koray Kavukcuoglu と Oriol Vinyals と、元 Google Brain 責任者 Jeff Dean によって共同で率いられています。

Gemini は、Youtube での 93 億 6,000 万分のビデオ字幕トレーニングを使用して、大規模モデルと AI 画像生成の機能を統合し、総データ セット サイズは GPT-4 の 2 倍になると推定されています。
元DeepMind創設者のハサビス氏は、ジェミニがAlphaGoタイプのシステムの一部の機能を「他の非常に興味深いイノベーション」と組み合わせる予定であることを明らかにした。
さらに、Google の創設者である Brin も、モデルの評価やトレーニングの支援など、Gemini の開発に個人的に関与しています。
Gemini に関するこれ以上具体的なニュースはありませんが、GPT-4 のような MoE アーキテクチャと投機的サンプリング テクノロジーも使用するのではないかと推測する人もいます。
8月上旬にGoogle DeepMindによって出版された新しい論文「From Sparse to Soft Mixtures of Experts」は、ジェミニに関連している可能性があると考えられています。

具体的には、小規模モデルに事前にいくつかのトークンを生成させ、大きなモデルに判定を行わせ、承認された場合は、大きなモデルに次のトークンを生成させ、最初のステップを繰り返します。 、ビッグモデルに切り替えます。
Googleの推測的なサンプリング論文は2022年11月まで公開されないが、これまでの暴露によれば、GPT-4も同様のテクノロジーを使用していることが示唆されている。

Noam Shazeer は、Google に在籍していたときに、今日の大規模モデルにとって非常に重要な Transformer、MoE、投機的サンプリングの研究に参加したほか、T5、LaMDA、PaLM などの複数の大規模モデルの研究にも参加しました。 。
セミアナリシスのレポートでは、彼のゴシップの一つも語られています。
GPT-2 時代の早い段階で、Noam Shazeer は Google の内部メモを書き、将来、大規模なモデルがさまざまな方法で人々の生活に統合されるだろうと予測していましたが、この見解は当時 Google によって真剣に受け止められませんでした。
現在、彼が予測したことの多くは、ChatGPT のリリース後に実際に起こったようです。
しかし、Noam Shazeer 氏は 2021 年に Character.ai を開始するために Google を辞めました。このレポートによると、彼も現在「GPU 貧乏人」の一員になっています。
参考リンク: [1] [2] [3] [4]