Sumber: Qubit
Saat saya terbangun di malam hari, ada kabar hangat di kalangan model besar - “GPU-Poor” (GPU-Poor).
Laporan dari SemiAnalysis, sebuah organisasi analisis industri, menyampaikan berita bahwa Google memiliki lebih banyak sumber daya komputasi daripada gabungan OpenAI, Meta, Amazon, Oracle, dan CoreWeave.
Analis Dylan Patel memperkirakan bahwa pada akhir tahun ini, model skala besar generasi berikutnya Gemini yang dikembangkan bersama oleh Google DeepMind akan mengalahkan (Smash) GPT-4 hingga mencapai 5 kali dari GPT-4.
Laporan tersebut menunjukkan bahwa dalam menghadapi keuntungan yang luar biasa ini, sebagian besar startup dan perusahaan open source telah menjadi “miskin GPU”, berjuang dengan sumber daya yang terbatas.
Pernyataan yang menarik perhatian dan menyayat hati ini dengan cepat menjadi meme baru dan menyebar di industri.
 Meme paling populer terakhir kali adalah “tidak ada parit”. Secara kebetulan, ini dibuat oleh penulis yang sama, dan dia juga yang membeberkan detail arsitektur internal GPT-4.
Meme paling populer terakhir kali adalah “tidak ada parit”. Secara kebetulan, ini dibuat oleh penulis yang sama, dan dia juga yang membeberkan detail arsitektur internal GPT-4.
Julien Chaumond, salah satu pendiri HuggingFace, pemimpin open source, mengatakan: Jangan meremehkan kami, orang-orang miskin.
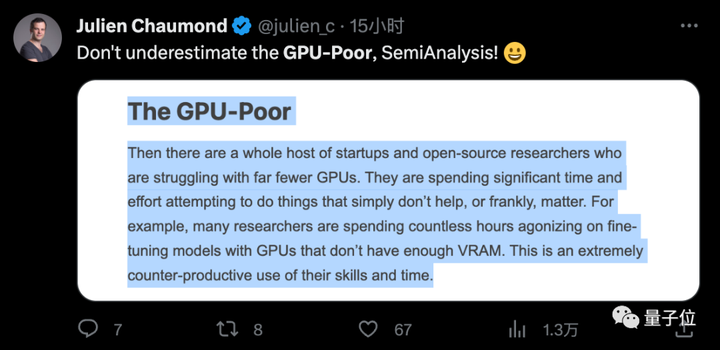 Beberapa orang juga mengeluh secara online atas nama mahasiswa: Kami miskin dalam hal uang dan lemah dalam daya komputasi, dan mereka membicarakan kami sebagai mahasiswa doktoral.
Beberapa orang juga mengeluh secara online atas nama mahasiswa: Kami miskin dalam hal uang dan lemah dalam daya komputasi, dan mereka membicarakan kami sebagai mahasiswa doktoral.
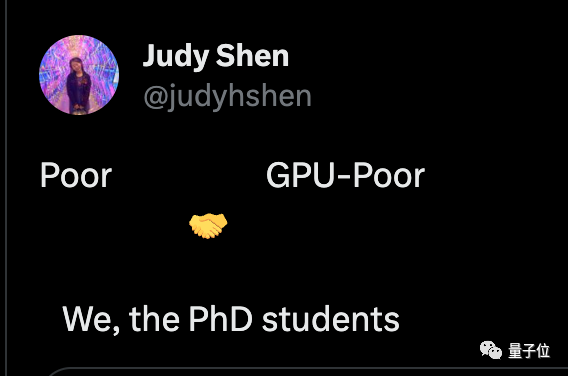 Chen Tianqi, seorang sarjana terkenal yang bekerja membuat ponsel menjalankan model besar, mengatakan bahwa setiap orang akan memiliki asisten AI sendiri di masa depan, dan kebanyakan dari mereka akan “miskin GPU”, tapi jangan meremehkan totalnya. jumlah.
Chen Tianqi, seorang sarjana terkenal yang bekerja membuat ponsel menjalankan model besar, mengatakan bahwa setiap orang akan memiliki asisten AI sendiri di masa depan, dan kebanyakan dari mereka akan “miskin GPU”, tapi jangan meremehkan totalnya. jumlah.
 Ada juga banyak orang yang percaya bahwa, terlepas dari konten kontroversial dan sebagian besar biaya konten, kata pengantar gratis dari laporan ini adalah kritik dan ringkasan yang bagus tentang situasi industri model skala besar saat ini.
Ada juga banyak orang yang percaya bahwa, terlepas dari konten kontroversial dan sebagian besar biaya konten, kata pengantar gratis dari laporan ini adalah kritik dan ringkasan yang bagus tentang situasi industri model skala besar saat ini.
“GPU buruk” melakukan pekerjaan yang tidak berguna
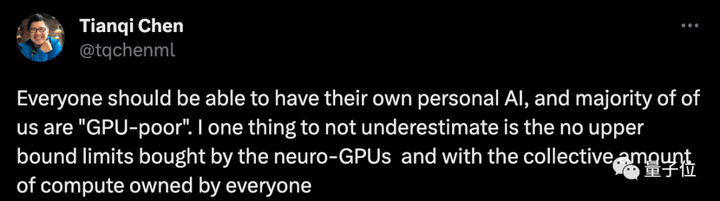
Laporan tersebut sangat kejam dan blak-blakan menyatakan bahwa banyak startup yang menghabiskan banyak waktu dan tenaga untuk melakukan hal-hal yang sia-sia ketika mereka kekurangan GPU.
Misalnya, banyak orang yang ingin menggunakan keluaran model besar untuk menyempurnakan model kecil, lalu pergi ke sapuan papan peringkat, tetapi metode evaluasinya tidak sempurna, dan lebih memperhatikan gaya daripada akurasi atau kepraktisan.
Laporan tersebut juga meyakini bahwa pemeringkatan itu sendiri dengan berbagai standar pengukuran juga menyesatkan perusahaan kecil, sehingga menghasilkan sejumlah besar model yang tidak praktis, yang juga merupakan kerugian bagi gerakan open source.
Di sisi lain, masyarakat miskin GPU tidak menggunakan sumber daya secara efisien, dan kebanyakan dari mereka menggunakan model padat, yang sebagian besar didasarkan pada ekosistem alpaka open source.
Namun, raksasa seperti OpenAI dan Google sudah bermain dengan model yang jarang** seperti arsitektur MoE, dan menggunakan model kecil** pengambilan sampel spekulatif (decoding spekulatif) untuk meningkatkan efisiensi penalaran, sepenuhnya dua permainan.
Penulis berharap bahwa GPU yang buruk tidak boleh terlalu membatasi ukuran model dan melakukan kuantisasi yang berlebihan, sambil mengabaikan penurunan kualitas model. Perusahaan harus berfokus pada penyediaan model yang disempurnakan secara efisien pada infrastruktur bersama, mengurangi latensi dan kebutuhan bandwidth memori, memenuhi kebutuhan komputasi edge.
Melihat hal tersebut, sebagian orang pun mengutarakan pendapat berbeda, meyakini bahwa terobosan kreatif seringkali datang dari lingkungan yang terbatas, yang justru merupakan sebuah keuntungan.
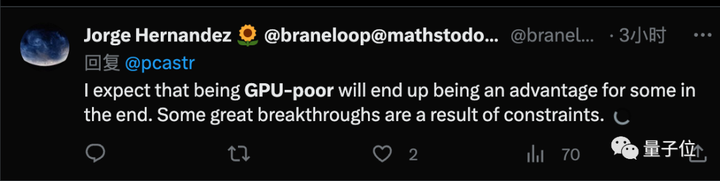 Namun salah satu pendiri Perplexity.AI, Aravind Srinivas, yakin bahwa organisasi yang kaya akan GPU sebenarnya akan berinvestasi dalam penelitian meskipun ada kendala.
Namun salah satu pendiri Perplexity.AI, Aravind Srinivas, yakin bahwa organisasi yang kaya akan GPU sebenarnya akan berinvestasi dalam penelitian meskipun ada kendala.
Dan untuk menemukan terobosan berikutnya seperti Transformer, diperlukan ribuan eksperimen, dan sumber daya yang dibutuhkan pasti tidak sedikit.

Cara memainkan game “GPU Rich”
Jadi di sisi lain warga GPU, apa yang dilakukan Google, “tiran lokal GPU”? .
Sebenarnya, kekuatan komputasi Google bukanlah GPU melainkan TPU miliknya sendiri. Laporan tersebut meyakini bahwa meskipun kinerja unit tunggal TPUv5 tidak sebaik NVIDIA H100, Google memiliki arsitektur infrastruktur paling efisien.
Setelah penggabungan Google Brain dan DeepMind, mereka bersama-sama melatih model besar Gemini melawan GPT-4.
Sebuah tim yang terdiri dari 100 orang dipimpin bersama oleh dua mantan VP penelitian DeepMind Koray Kavukcuoglu dan Oriol Vinyals serta mantan kepala Google Brain Jeff Dean.
 Menurut berbagai laporan, Gemini diperkirakan akan dirilis dalam tahun, lebih tepatnya, pada rentang musim gugur Amerika Serikat (23 September-21 Desember).
Menurut berbagai laporan, Gemini diperkirakan akan dirilis dalam tahun, lebih tepatnya, pada rentang musim gugur Amerika Serikat (23 September-21 Desember).
Gemini akan mengintegrasikan kemampuan model besar dan pembuatan gambar AI, menggunakan 9,36 miliar menit pelatihan subtitle video di Youtube, dan total ukuran kumpulan data diperkirakan dua kali lipat dari GPT-4.
Mantan pendiri DeepMind, Hassabis, mengungkapkan bahwa Gemini akan menggabungkan beberapa kemampuan sistem tipe AlphaGo dengan “inovasi lain yang sangat menarik”.
Selain itu, pendiri Google, Brin, secara pribadi terlibat dalam penelitian dan pengembangan Gemini, termasuk mengevaluasi model dan membantu pelatihan.
Tidak ada berita yang lebih spesifik tentang Gemini, namun beberapa orang berspekulasi bahwa Gemini juga akan menggunakan arsitektur MoE dan teknologi pengambilan sampel spekulatif yang sama seperti GPT-4.
Sebuah makalah baru, From Sparse to Soft Mixtures of Experts yang diterbitkan oleh Google DeepMind pada awal Agustus, dianggap mungkin terkait dengan Gemini.
 Pengambilan sampel spekulatif dapat mempercepat inferensi 2-3 kali lipat untuk model Transformer besar tanpa kehilangan kualitas pembangkitan.
Pengambilan sampel spekulatif dapat mempercepat inferensi 2-3 kali lipat untuk model Transformer besar tanpa kehilangan kualitas pembangkitan.
Secara khusus, biarkan model kecil menghasilkan beberapa token terlebih dahulu dan biarkan model besar membuat penilaian. Jika diterima, biarkan model besar menghasilkan token berikutnya dan ulangi langkah pertama. Jika kualitas model kecil tidak tinggi, kemudian beralih ke model besar.
Makalah pengambilan sampel spekulatif Google tidak akan dipublikasikan hingga November 2022, tetapi informasi sebelumnya menunjukkan bahwa GPT-4 juga menggunakan teknologi serupa.
 Faktanya, pendahulu teknologi pengambilan sampel spekulatif, Blockwise Parallel Decoding, juga berasal dari Google, dan penulisnya termasuk Noam Shazeer, salah satu penulis Transformer.
Faktanya, pendahulu teknologi pengambilan sampel spekulatif, Blockwise Parallel Decoding, juga berasal dari Google, dan penulisnya termasuk Noam Shazeer, salah satu penulis Transformer.
Noam Shazeer berpartisipasi dalam penelitian Transformer, MoE, dan pengambilan sampel spekulatif ketika dia berada di Google, yang sangat penting untuk model besar saat ini. Selain itu, dia juga berpartisipasi dalam penelitian beberapa model besar seperti T5, LaMDA, dan PaLM .
Laporan SemiAnalysis juga menceritakan salah satu gosipnya.
Pada awal era GPT-2, Noam Shazeer menulis memo internal di Google, memperkirakan bahwa model besar akan diintegrasikan ke dalam kehidupan masyarakat dengan berbagai cara di masa depan, namun pandangan ini tidak ditanggapi serius oleh Google pada saat itu.
Kini tampaknya banyak hal yang diprediksinya benar-benar terjadi setelah ChatGPT dirilis.
Namun, Noam Shazeer meninggalkan Google pada tahun 2021 untuk mendirikan Character.ai, menurut laporan ini, dia sekarang juga termasuk dalam “GPU miskin”.
Tautan referensi:
[1]
[2]
[3]
[4]